
The Truth
October 21, 2009 2:00 PM by Daniel Chambers
Recently I was presented with a moral issue that made me reflect on what the truth actually is. I consider myself to be a very honest person; in fact, I hate lying and people that lie. Lying never ever benefits you in the long term. Sure, you can spin a web of lies in the short term to your benefit, but to maintain your web you will need to continuously spin more strands to patch holes that develop over time. Eventually, your web of lies will become so complex that you or someone else will trip over a strand and fall, taking out the entire web and making you look extremely bad. From then on, people will be unable to trust what you tell them thereby devaluing anything you have to say. I find it far better policy to just tell the truth up front, regardless of the immediate cost, because if you lie you will eventually be caught out and the cost will be far worse than the cost of telling the truth up front.
The moral issue I encountered was over half-truths, or "spinning". Spinning is where you "present the facts" in a light that makes them look better than they are. You probably do this by colouring your language to bias it one way or another, or by omitting certain truths and only leaving the truths that make you, or whatever it is you are arguing for, sound good. To me, this is lying. Why? Well, let's define what a lie is.
The dictionary says a lie is "a false statement made with deliberate intent to deceive; something intended or serving to convey a false impression". Spinning and half-truths fall squarely in the latter definition's bucket. By omitting certain facts, you are deliberately "serving to convey a false impression". I would call half-truths "lying by omission".
Let me present an example. Say you see an ad for a hypothetical new cream that removes wrinkles from your aging face. However, the makers of the cream know that if you use the cream for over two weeks you begin to develop rashes on your face. If they deliberately don't tell you this in the ad, one could say they are not lying, since they have not said any untruths. I deny this assertion. By deliberately omitting the truth that the cream causes rashes, they are lying to the consumer about how good the product is so as to get people to buy it. If the ad said, "miraculous cream that removes wrinkles, but gives rashes", would you buy it? I think not.
The specific issue I have encountered is to do with a software solution that a team that I am working on is delivering to our client in the next few weeks. Unfortunately, even though we've worked as hard as we could have, we haven't been able meet all the requirements that we promised the client due to simply running out of time. We've been told that when we present the product to the client, we shouldn't tell them about the requirements that we have not met, and instead tell them about the ones we have met. We'll then tell them about the missed requirements in our documentation and in later presentations to them (presentations where I gather the bigwigs will not be there). Apparently, because we are telling them about the unmet requirements later on, that makes not telling them about them now okay.
You might think that not telling them up front about not meeting some of the requirements might be okay if the requirements that were not met were trivial. After all, why let some small stuff overshadow the larger achievements of the project? However, in our case, it is not trivial requirements that we are missing; we are not fully meeting critical main requirements. I argued that if we're not meeting these requirements fully, when we present the product to them, we should be truthful and say "we've managed to meet part of the critical requirement, but there's a major part that, due to time constraints, we weren't able to cover". However, we were told that, no, we shouldn't tell them about it at this presentation because it would tarnish the project.
To me, this is just a case of lying by omission. We are literally "conveying a false impression", which is the definition of lying. The client will think "great, they've met our requirements and we've got a working product". However, when they actually go to use it, or read the documentation, or listen to our later presentations, they will see and be told that, in fact, we are not meeting their requirements, and they are getting an incomplete product. Then we'll look like liars.
We're obviously being told to do this to make us look good, but would it really be that bad if we manned up and just told them the truth? I'm sure they'd appreciate our honesty, and since we honestly did do our utmost to try and meet the requirements, we really can't be faulted for anything other than perhaps promising more than we could deliver in the time allocated. And since this is a university project for an external client and they're not paying for it, I can't really see them getting too angry over it and suing us or something.
If we don't tell them about it in that product presentation, I can imagine that when we come to the later presentation and go "oh, it performs your needed functionality, except in these rather common cases where it just won't work", they're going to frown at us and go "but you said before that it did all that". And that'd be where we go, "yeah...", and look like fools. I think that getting their expectations pumped up and then smashing them will leave a worse taste in their mouths than actually telling them about it up front.
In conclusion, I believe that you can either speak the truth, or you can lie. There is no middle ground, no half-truths. Deliberately biasing the "truth" to control another person's perception is nothing more than creating falsehood. Why else does one try to make decisions off of objective, unbiased facts? Subjective, biased "truths" are not the truth and therefore cannot be used to make firm decisions off of. Lying can never benefit you because eventually you will be caught out and forced to admit your untruths, and then people will never be able to trust you again. Telling anything other than the truth, regardless of whether it makes you look bad, is nothing other than lying. If you've screwed up, or something unexpected went wrong, man up and admit it.
Entity Framework Compiled Queries Bake in the MergeOption
September 24, 2009 2:00 PM by Daniel Chambers
Updated on 2009/09/26
I've had some unexpected behaviour with change tracking and compiled queries while using .NET 3.5 SP1's Entity Framework. It's something that you likely won't notice and the resultant bug acts like a race condition: it only exhibits itself when things are executed in a particular order. Unfortunately, the Entity Framework documentation doesn't seem to make this behaviour clear in its documentation, which leaves you scratching your head when it actually occurs.
ObjectQuery.MergeOption allows you to control how the Entity Framework handles objects with respect to change tracking. I tend to set it to MergeOption.NoTracking when I want all objects created from a particular LINQ query returned pre-detached from the ObjectContext (very useful in web apps). However, when you want to query some objects, change their details and save the changes back to the DB, you will use MergeOption.AppendOnly, which is the default. This causes the ObjectContext to "remember" your objects and track the changes you make to them so it knows what it needs to save back to the DB when you go SaveChanges() on the ObjectContext.
Let me paint you a scenario. Maybe you use compiled queries to make your Entity Framework code quick as a fox. Maybe you use them to do something simple like get a Product from a database by its ID:
public static readonly Func<AdvWorksEntities, int, Product>
GetProduct = CompiledQuery.Compile(
(AdvWorksEntities context, int id) =>
(from product in context.Product
where product.ProductID == id
select product).FirstOrDefault());
Maybe you have two methods that call that compiled query (these are rather contrived examples):
public Product GetProductById(int id)
{
using (AdvWorksEntities context = new AdvWorksEntities())
{
context.Product.MergeOption = MergeOption.NoTracking;
return CompiledQueries.GetProduct(context, id);
}
}
public void ChangeProductName(int id, string newName)
{
using (AdvWorksEntities context = new AdvWorksEntities())
{
Product product = CompiledQueries.GetProduct(context, id);
product.Name = newName;
context.SaveChanges();
}
}
Nothing looks immediately wrong with that code (well, it didn't to me anyway).
Maybe you've got a user who opens the View Product page. The GetProductById method is called and the GetProduct compiled query is compiled and run. The user then decided the product has a crappy name, and he/she wants to change it. They change the name, and ChangeProductName gets called. The user then sees that the product name has, in fact, not been changed and gets pissed off.
What went wrong? You, the brow-beaten developer, open Visual Studio, start the app, and call ChangeProductName, which causes the GetProduct compiled query to be compiled and run. It works okay, the name is changed succesfully, and you're left scratching your head. You call it again, and it works again! What the hell is going on?
You restart the app and step through exactly what the user did. You call the GetProductById method, then call ChangeProductName. Bam, silent failure! SaveChanges returns successfully but your changes were not saved to the DB! The query is the same, but it's like somehow the MergeOption.NoTracking is coming over from the call to GetProductId. But this doesn't make sense since you're using a whole new ObjectContext! At this point you're cursing Entity Framework and looking at the documentation, which says nothing (to be fair, when you look into the details like I did, it makes sense. But it's just unintuitive and odd, and really needs to be highlighted in the documentation explicitly).
When this situation happened to me, I created a small test app to try and figure out why this was occurring. Here's what I found. The very first use of the GetProduct query causes it to get compiled. The query itself uses the ObjectQuery (which is IQueryable) that you set the MergeOption on. The expression tree for this query is saved and used for every query from then on. And here's the key: the saved expression tree includes the MergeOption that you set. So if you use MergeOption.NoTracking on the very first call to that compiled query, every query done with that compiled query from then on will be a NoTracking query, since the MergeOption is baked into it. It doesn't matter than you pass the compiled query a different ObjectContext with a different ObjectQuery that has a different MergeOption set. It will forevermore be NoTracking.
So what can you do? At this point, it seems that you will need different compiled queries for the different MergeOptions. If you use GetProduct with NoTracking and with AppendOnly, you will now need GetProductWithNoTracking and GetProductWithAppendOnly.
So watch out for this issue; it's really easy to run into because the query's MergeOption is set outside of the compiled query's declaration, therefore it's not obvious that it is actually baked into the compiled query. And it's a pain to discover, because it doesn't crop up unless you execute your methods in a particular order.
Update: I've developed a solution that makes this problem easier to deal with: a class that transparently duplicates a compiled query, allowing you to easily have multiple versions of a compiled query, one per MergeOption. The solution is currently in the DigitallyCreated Utilities repository and the tutorial for it can be found here.
DigitallyCreated Utilities Now Open Source
August 05, 2009 2:00 PM by Daniel Chambers
My part time job for 2009 (while I study at university) has been working at a small company called Onset doing .NET development work. Among other things, I am (with a friend who also works there) re-writing their website in ASP.NET MVC. As I wrote code for their website I kept copy/pasting in code from previous projects and thinking about ways I could make development in ASP.NET MVC and Entity Framework even better.
I decided there needed to be a better way of keeping all this utility code that I kept importing from my personal projects into Onset's code base in one place. I also wanted a place that I could add further utilities as I wrote them and use them across all my projects, personal or commercial. So I took my utility code from my personal projects, implemented those cool ideas I had (on my time, not on Onset's!) and created the DigitallyCreated Utilities open source project on CodePlex. I've put the code out there under the Ms-PL licence, which basically lets you do anything with it.
The project is pretty small at the moment and only contains a handful of classes. However, it does contain some really cool functionality! The main feature at the moment is making it really really easy to do paging and sorting of data in ASP.NET MVC and Entity Framework. MVC doesn't come with any fancy controls, so you need to implement all the UI code for paging and sorting functionality yourself. I foresaw this becoming repetitive in my work on the Onset website, so I wrote a bunch of stuff that makes it ridiculously easy to do.
This is the part when I'd normally jump into some awesome code examples, but I already spent a chunk of time writing up a tutorial on the CodePlex wiki (which is really good by the way, and open source!), so go over there and check it out.
I'll be continuing to add to the project over time, so I thought I might need some "project values" to illustrate the quality level that I want the project to be at:
- To provide useful utilities and extensions to basic .NET functionality that saves developers' time
- To provide fully XML-documented source code (nothing is more annoying than undocumented code)
- To back up the source code documentation with useful tutorial articles that help developers use this project
That's not just guff: all the source code is fully documented and that tutorial I wrote is already up there. I hate open source projects that are badly documented; they have so much potential, but learning how they work and how to use them is always a pain in the arse. So I'm striving to not be like that.
The first release (v0.1.0) is already up there. I even learned how to use Sandcastle and Sandcastle Help File Builder to create a CHM copy of the API documentation for the release. So you can now view the XML documentation in its full MSDN-style glory when you download the release. The assemblies are accompanied by their XMLdoc files, so you get the documentation in Visual Studio as well.
Setting all this up took a bit of time, but I'm really happy with the result. I'm looking forward to adding more stuff to the project over time, although I might not have a lot of time to do so in the near future since uni is starting up again shortly. Hopefully you find what it has got as useful as I have.
ASP.NET MVC Compared to JSF
June 10, 2009 3:00 PM by Daniel Chambers
Updated on 2009/06/12 & 2009/06/13.
Today I'm going to do a little no-holds-barred comparison of ASP.NET MVC and JavaServer Faces (JSF) based on my impressions when working with the both of them. I worked with ASP.NET MVC in my Enterprise .NET university subject and with JSF in my Enterprise Java subject. Please note that this is in no way a scientific comparison of the two technologies and is simply my view of the matter based on my experiences.
ASP.NET MVC is the new extension to ASP.NET that allows you to write web pages using the Model View Controller pattern. Compared to the old ASP.NET Forms way of doing things, it's a breath of fresh air. JSF is one of the many Java-based web application frameworks that are available. It's basically an extension to JSP (JavaServer Pages), which is a page templating language similar to the way ASP.NET Forms works (except without the code-behind; so it's more like original ASP in that respect).
JSF Disadvantages
It is probably easiest if I start with what is wrong with JSF and what makes it a total pain in the arse to use (you can tell already which slant this post will take! :D)
Faces-Config.xml
In years past, the world went XML-crazy (this has lessened in recent years). Everybody was jumping aboard the XML train and putting everything they could into XML. The Faces-Config.xml is a result of this (in my opinion, anyway). It is basically one massive XML file where you define where every link on (almost) every page goes to. You also declare your "managed backing beans", which are just classes that the framework instantiates and manages the lifecycle (application, session, or per-request) of. In addition, you can declare extensions to JSF like custom validators, among other things.
All of this goes into the one XML file. As you can probably see, it soon becomes huge and unwieldy. Also, when working in a team, everybody is always editing this file and as such nasty merge conflicts often occur.
Page Navigation
In JSF, you need to define where all your links go in your faces-config.xml. You can do stuff like wildcards (which lets you describe where a link from any page goes) to help ease this pain, but it still sucks.
Not only that, but every page link in JSF is a POST->Redirect, GET->Response. Yes, that's right, every click is a form submit and redirect. Even from a normal page to the next. If you don't perform the redirect, JSF will still show you the next page, but it shows it under the previous page's URL (kind of like an ASP.NET Server.Transfer).
No Page Templating Support
It seems like a simple thing, but JSF just doesn't have any page templating support (called Master Pages in ASP.NET). This makes keeping a site layout consistent a real pain. We ended up resorting to using Dreamweaver Templates (basically just advanced copy & paste) to keep our site layout consistent. Yuck.
Awkward Communication Between Pages and Between Objects
In JSF, it is awkward and difficult to communicate data between pages. JSF doesn't really support URL query string parameters (since every link is a POST), so you end up having to create an object that sticks around for the user's session and then putting the data that you want on the next page in that, ready for the next page to get. Yuck. There are other approaches, but none of them are really very easy to do.
Communication between "managed backing beans" is awkward. You end up having to manually compile a JSP Expression Language statement to get at other backing beans. Check out this page to see all the awkward contortions you need to do to achieve anything.
ASP.NET MVC vs. JSF Disadvantages
So enough JSF bashing. It's all very well to beat on JSF, but can ASP.NET MVC do all those things that JSF can't do well? The answer is yes, yes it can.
Little XML Configuration
Other than the web.xml file, where you initialise a lot of ASP.NET MVC settings (like integration with IIS, Membership, Roles, Database connection strings, etc), ASP.NET MVC doesn't use any XML. The things that you do have to do in the web.xml are likely things you'll set up once and never touch again, and so are unlikely to cause messy merge conflicts in revision control. Even user authorisation for page access is not done in XML (unlike JSF, and for that matter, ASP.NET Forms); it's done with attributes in the code.
RESTful URLs and Page Navigation
ASP.NET MVC has a powerful URL routing engine that allows (and encourages) you to use RESTful URLs. When you create page links, ASP.NET MVC automatically creates the correct the URL to the particular action (on a controller) that you want to perform by doing a reverse lookup in the routing table. No double page requests here, and if you change what your URLs look like you don't need to update all your links, you just change the routing table.
Master Pages
ASP.NET MVC inherits the concept of Master Pages from ASP.NET Forms. Master pages let you easily define what every page has in common, then for each page, define only what varies. It's a powerful templating technology.
Easy Communication Between Pages
Communication between pages is easy in ASP.NET MVC since it fully supports getting data from both POST and GET (URL query string parameters). It also provides a neat "TempData" store that you can place things in that will be passed on to the next page loaded, and then are automatically destroyed. This is extremely useful for passing a message onto the next page for it to display an "operation performed" message after a form submit.
JSF Advantages
As much as I dislike JSF, it does have a few things going for it that ASP.NET MVC just doesn't have.
Multi-platform Support
One of the biggest criticisms of any .NET technology is that it only runs on Windows. And while I may be a big fan of Windows, when it comes to servers, other operating systems can be viable alternatives. JSF gives you the flexibility to choose what operating system you want to run your web application on.
Multiple Implementations and Multiple Web Application Server Support
JSF is a standard, so there are many different implementations of the standard. This means that you can pick and choose which particular implementation best suits your needs (in terms of performance, etc). This encourages competition and ultimately leads to better software.
JSF can run in many different application servers, which gives you the choice of which you'd like to use. Feeling cheap? Use Glassfish, Sun's free application server. Feeling rich and in need of features? Use IBM WebSphere. Feeling the need for speed and no need for those all enterprise technologies like EJBs? Crack out Tomcat.
The Java Ecosystem
Like it or not, Java has a massive following and open-source ecosystem. If you need something, it's probably been done before and is open-source and therefore you can get it for free (probably... if you're closed-source you need to watch out for GPLed software).
Free
JSF is free, Java is free, and you can run it all on free operating systems and application servers, you can get a JSF web application up and running for nothing (excluding programming labour, of course).
ASP.NET MVC vs. JSF Advantages
So how does ASP.NET MVC weigh up against the pros of JSF? Not too well.
Only Runs on Windows
ASP.NET MVC will only run on Windows, since it runs on the .NET Framework. You could argue that Mono exists for Linux, but the Mono .NET implementation is always behind Microsoft's implementation, so you can never get the latest technology (and ASP.NET MVC is very recent).
Only Runs in One Application Server
ASP.NET MVC runs in only one application server: IIS. If IIS doesn't do what you want, or doesn't perform like you need it to, too bad, you've got no choice but to use it.
Update: A friend told me about how you can actually run ASP.NET in Apache. However, that plugin (mod_aspdot) was retired from Apache due to lack of support. Its successor, mod_mono, allows you to run ASP.NET in Apache using Mono. However, at the time of writing I see multiple tests failing on their test page. I don't know how severe these bugs are, but it's certainly not the level of support you receive from Microsoft in IIS.
Decent Ecosystem
Most people probably would have assumed I would bash the .NET ecosystem for not being very open source and that is true, up to a point. However, in recent times the .NET ecosystem has been becoming more and more open-source. ASP.NET MVC itself is open source! All this said and done, Java is still far more open-source and free than .NET.
Not Really Free
Although you can download the .NET SDK for free, you really do need to purchase Visual Studio to be effective while developing for it. You'll also need to pay for Windows on which to run your web server.
ASP.NET MVC Other Advantages
Other than all the sweet stuff I mentioned above, what else does ASP.NET MVC have to offer?
Clean Code Design
ASP.NET MVC makes it very easy to write neat, clean and well designed code because of its use of the Model View Controller pattern. JSF is supposedly MVC, but I honestly couldn't tell how they were using it. My code in JSF was horrible and awkward. ASP.NET MVC is clearly MVC and benefits a lot from it. You can unit test your controllers easily, and your processing logic is kept well away from your views.
Support for Web 2.0 Technologies
Web 2.0 is a buzzword that represents (in my mind) the use of JavaScript and AJAX to make web pages more rich and dynamic. ASP.NET makes it pretty easy to support these technologies and even comes with fully supported and documented jQuery support. JSF doesn't come with any of this stuff ready and out of the box and due to its awkward page navigation system, makes it difficult to incorporate one of the existing technologies into it. The JSF way is most definitely not the Web 2.0 way.
Visual Studio
Although you have to pay for Visual Studio, it is an excellent IDE to work with ASP.NET MVC in. NetBeans, the IDE I used JSF in, was quite possibly one of the worst IDEs I have ever used. It was awkward to use, slow, unintuitive and buggy. Visual Studio has an inbuilt, lightweight web server that you can run your web applications on while developing. You just build your application and, bam, it's already automatically running. In NetBeans, you have to deploy the application (slow!) to GlassFish and sometimes it will bollocks it up somehow and you'll just get random uncaught exceptions that a clean and build and redeploy will somehow fix. That sort of annoying, time-wasting and confusing stuff just doesn't occur in Visual Studio. You really do get what you pay for.
In conclusion, I feel that ASP.NET MVC is a far better Web Application Framework than JSF. It makes it so easy to code neat and well-designed pages that generate modern Web 2.0-style pages. JSF just ends up getting in your way. While coding ASP.NET MVC, I kept going "oh wow, that's nice!", but while developing JSF I just swore horribly. And that really tells you something.
Update: I've been told that JSF 2.0 (as yet unreleased at the time of writing) fixes many of the problems I've mentioned above. So, it might be worth a re-evaluation once it is released.
WCF Authentication at both Transport and Message Level
June 10, 2009 2:00 PM by Daniel Chambers
Let's say you've got a web service that exposes data (we could hardly say that you didn't! :D). This particular data always relates to a particular user; for example, financial transactions are always viewed from the perspective of the "user". If it's me, it's my transactions. If it's you, it's your transactions. This means every call to the web service needs to identify who the user is (or you can use a session, but let's put that idea aside for now).
However, lets also say that these calls are "on behalf" of the user and not from them directly. So we need a way of authenticating who is putting the call through on behalf of the user.
This scenario can occur in a user-centric web application, where the web application runs on its own server and talks to a business service on a separate server. The web application server talks on behalf of the user with the business server.
So wouldn't it be nice if we could do the following with the WCF service that enables the web application server to talk to the business server: authenticate the user at the message level using their username and password and authenticate the web application server at the transport level by checking its certificate to ensure that it is an expected and trusted server?
Currently in WCF the out-of-the-box bindings net.tcp and WSHttp offer authentication at either message level or the transport level, but not both. TransportWithMessageCredential security is exactly that: transport security (encryption) with credentials at the message level. So how can we authenticate at both the transport and message level then?
The answer: create a custom binding (note: I will focus on using the net.tcp binding as a base here). I found the easiest way to do this is to continue doing your configuration in the XML, but at runtime copy and slightly modify the netTcp binding from the XML configuration. There is literally one switch you need to enable. Here's the code on the service side:
ServiceHost businessHost = new ServiceHost(typeof(DHTestBusinessService));
ServiceEndpoint endpoint = businessHost.Description.Endpoints[0];
BindingElementCollection bindingElements = endpoint.Binding.CreateBindingElements();
SslStreamSecurityBindingElement sslElement = bindingElements.Find<SslStreamSecurityBindingElement>();
//Turn on client certificate validation
sslElement.RequireClientCertificate = true;
CustomBinding newBinding = new CustomBinding(bindingElements);
NetTcpBinding oldBinding = (NetTcpBinding)endpoint.Binding;
newBinding.Namespace = oldBinding.Namespace;
endpoint.Binding = newBinding;
Note that you need to run this code before you Open() on your ServiceHost.
You do exactly the same thing on the client side, except you get the ServiceEndpoint in a slightly different manner:
DHTestBusinessServiceClient client = new DHTestBusinessServiceClient(); ServiceEndpoint endpoint = client.Endpoint; //Same code as the service goes here
You'd think that'd be it, but you'd be wrong. :) This is where it gets extra lame. You're probably attributing your concrete service methods with PrincipalPermission to restrict access based on the roles of the service user, like this:
[PrincipalPermission(SecurityAction.Demand, Role = "MyRole")]
This technique will start failing once you apply the above changes. The reason is because the user's PrimaryIdentity (which you get from OperationContext.Current.ServiceSecurityContext.PrimaryIdentity) will end up being an unknown, username-less, unauthenticated IIdentity. This is because there are actually two identities representing the user: one for the X509 certificate used to authenticate over Transport, and one for the username and password credentials used to authenticate at Message level. When I reverse engineered the WCF binaries to see why it wasn't giving me the PrimaryIdentity I found that it has an explicit line of code that causes it to return that empty IIdentity if it finds more than one IIdentity. I guess it's because it's got no way to figure out which one is the primary one.
This means using the PrincipalPermission attribute is out the window. Instead, I wrote a method to mimic its functionality that can deal with multiple IIdentities:
private void AssertPermissions(IEnumerable<string> rolesDemanded)
{
IList<IIdentity> identities = OperationContext.Current.ServiceSecurityContext.AuthorizationContext.Properties["Identities"] as IList<IIdentity>;
if (identities == null)
throw new SecurityException("Unauthenticated access. No identities provided.");
foreach (IIdentity identity in identities)
{
if (identity.IsAuthenticated == false)
throw new SecurityException("Unauthenticated identity: " + identity.Name);
}
IIdentity usernameIdentity = identities.Where(id => id.GetType().Equals(typeof(GenericIdentity)))
.SingleOrDefault();
string[] userRoles = Roles.GetRolesForUser(usernameIdentity.Name);
foreach (string demandedRole in rolesDemanded)
{
if (userRoles.Contains(demandedRole) == false)
throw new SecurityException("Access denied: authorisation failure.");
}
}
It's not pretty (especially the way I detect the username/password credential IIdentity), but it works! Now, at the top of your service methods you need to call it like this:
AssertPermissions(new [] {"MyRole"});
Ensure that your client is providing a client certificate to the server by setting the client certificate element in your XML config under an endpoint behaviour's client credentials section:
<clientCertificate storeLocation="LocalMachine"
storeName="My"
x509FindType="FindBySubjectDistinguishedName"
findValue="CN=mycertficatename"/>
Now, I mentioned earlier that the business web service should be authenticating the web application server clients using these provided certificates. You could use chain trust (see the Chain Trust and Certificate Authorities section of this page for more information) to accept any client that was signed by any of the default root authorities, but this doesn't really provide exact authentication as to who is allowed to connect. This is because any server that has a certificate that is signed by any trusted authority will authenticate fine! What you need is to create your own certificate authority and issue your own certificates to your clients (I covered this process in a previous blog titled "Using Makecert to Create Certificates for Development").
However, to get WCF to only accept clients signed by a specific authority you need to write your own certificate validator to plug into the WCF service. You do this by inheriting from the X509CertificateValidator class like this:
public class DHCertificateValidator
: X509CertificateValidator
{
private static readonly X509CertificateValidator ChainTrustValidator;
private const X509RevocationMode ChainTrustRevocationMode = X509RevocationMode.NoCheck;
private const StoreLocation AuthorityCertStoreLocation = StoreLocation.LocalMachine;
private const StoreName AuthorityCertStoreName = StoreName.Root;
private const string AuthorityCertThumbprint = "e12205f07ce5b101f0ae8f1da76716e545951b22";
static DHCertificateValidator()
{
X509ChainPolicy policy = new X509ChainPolicy();
policy.RevocationMode = ChainTrustRevocationMode;
ChainTrustValidator = CreateChainTrustValidator(true, policy);
}
public override void Validate(X509Certificate2 certificate)
{
ChainTrustValidator.Validate(certificate);
X509Store store = new X509Store(AuthorityCertStoreName, AuthorityCertStoreLocation);
store.Open(OpenFlags.ReadOnly);
X509Certificate2Collection certs = store.Certificates.Find(X509FindType.FindBySubjectDistinguishedName, certificate.IssuerName.Name, true);
if (certs.Count != 1)
throw new SecurityTokenValidationException("Cannot find the root authority certificate");
X509Certificate2 rootAuthorityCert = certs[0];
if (String.Compare(rootAuthorityCert.Thumbprint, AuthorityCertThumbprint, true) != 0)
throw new SecurityTokenValidationException("Not signed by our certificate authority");
store.Close();
}
}
As you can see, the class re-uses the WCF chain trust mechanism to ensure that the certificate still passes chain trust requirements. But it then goes a step further and looks up the issuing certificate in the computer's certificate repository to ensure that it is the correct authority. The "correct" authority is defined by the certificate thumbprint defined as a constant at the top of the class. You can get this from any certificate by inspecting its properties. (As an improvement to this class, it might be beneficial for you to replace the constants at the top of the class with configurable options dragged from a configuration file).
To configure the WCF service to use this validator you need to set the some settings on the authentication element in your XML config under the service behaviour's service credential's client certificate section, like this:
<authentication certificateValidationMode="Custom"
customCertificateValidatorType="DigitallyCreated.DH.Business.DHCertificateValidator, MyAssemblyName"
trustedStoreLocation="LocalMachine"
revocationMode="NoCheck" />
And that's it! Now you are authenticating at transport level as well as at message level using certificates and usernames and passwords!
This post was derived from my question at StackOverflow and the answer that I researched up and posted (to answer my own question). See the StackOverflow question here.
Programming to an Interface when using a WCF Service Client
June 09, 2009 3:00 PM by Daniel Chambers
Programming to an interface and not an implementation is one of the big object-oriented design principles. So, when working with a web service client auto-generated by WCF, you will want to program to the service interface rather than the client class. However, as it currently stands this is made a little awkward.
Why? Because the WCF service client class is IDisposable and therefore needs to be explicitly disposed after you've finished using it. The easiest way to do this in C# is to use a using block. A using block takes an IDisposable, and when the block is exited, either by exiting the block normally, or if you quit it early by throwing an exception or something similar, it will automatically call Dispose() on your IDisposable.
The problem lies in the fact that, although the WCF service client implements IDisposable, the service interface does not. This means you either have to cast to the concrete client type and call Dispose() or you have to manually check to see whether the service-interfaced object you posses is IDisposable and if it is then Dispose() it. That is obviously a clunky and error-prone way of doing it.
Here's the way I solved the problem. It's not totally pretty, but it's a lot better than doing the above hacks. Firstly, because you are programming to an abstract interface, you need to have a factory class that creates your concrete objects. This factory returns the concrete client object wrapped in a DisposableWrapper. DisposableWrapper is a generic class I created that aids in abstracting away whether or not the concrete class is IDisposable or not. Here's the code:
public class DisposableWrapper<T> : IDisposable
{
private readonly T _Object;
public DisposableWrapper(T objectToWrap)
{
_Object = objectToWrap;
}
public T Object
{
get { return _Object; }
}
public void Dispose()
{
IDisposable disposable = _Object as IDisposable;
if (disposable != null)
disposable.Dispose();
}
}
The service client factory method that creates the service looks like this:
public static DisposableWrapper<IAuthAndAuthService> CreateAuthAndAuthService()
{
return new DisposableWrapper<IAuthAndAuthService>(new AuthAndAuthServiceClient());
}
Then, when you use the factory method, you do this:
using (DisposableWrapper<IAuthAndAuthService> clientWrapper = ServiceClientFactory.CreateAuthAndAuthService())
{
IAuthAndAuthService client = clientWrapper.Object;
//Do your work with the client here
}
As you can see, the factory method returns the concrete service client wrapper in a DisposableWrapper, but exposed as the interface because it the interface type as the generic type for DisposableWrapper. You call the factory method and use its resulting DisposableWrapper inside your using block. The DisposableWrapper ensures that the object it wraps, if it is indeed IDisposable, is disposed when it itself is disposed by the using block. You can get the client object out of the wrapper, but as the service interface type and not the concrete type, which ensures you are programming to the interface and not the implementation.
All in all, it's a fairly neat way to program against a service interface, while still retaining the ability to Dispose() the service client object.
Using Makecert to Create Certificates for Development
June 09, 2009 2:00 PM by Daniel Chambers (last modified on March 22, 2010 5:35 AM)
When I first needed to use certificates to secure my WCF service, I didn't really understand how certificates worked, how to create them, and where they go. A lot of the tutorials on the web just give you a raw makecert command that you black-box and trust works to create your certificate. But do you really know what it's doing? This is what I will explain today, although not in excruciating detail. Just enough to know what's going on.
Firstly, a few concepts. Certificates are a type of identification that try to ensure that you know who you are talking to, and that it is not somebody else just impersonating the person you are expecting to be talking to. In more technical terms, a certificate binds together a name (an identity) and a public key.
But if anyone could just create their own certificates, they could declare themselves to be anyone, right? For example, I could create a certificate whose name is "google.com", but I'm not really Google. This is where Certificate Authorities step in. These organisations are able to issue certificates to people, thereby ensuring that the identity declared on the certificate is actually the identity of the person holding the certificate. For example, if I went to Thawte (or some other authority) and said I wanted a certificate for "google.com", they would tell me to get stuffed (perhaps more politely, though).
So how does this authority-issuing-thing work? A certificate authority themselves have a certificate with which they digitally sign all the certificates they issue. My computer (and pretty much everyone's) has a store of the certificates of these different certificate authorities. The computer then knows that if its sees any certificate that has been signed by one of these trusted certificate authorities' certificate, then the computer should trust that certificate. This concept is called "Chain Trust". The "chain" part refers to the "chain" of certificates-signing-certificates.
So during development, we may want to create certificates for our own purposes and then implicitly trust them. We don't really want to go to a certificate authority and get a signed certificate, because that costs money and we're cheap. Instead, what we can do is create our own certificate authority and then issue certificates to ourselves to use. We place this fake certificate authority's certificate in our computer's trusted certificate authorities store thereby causing our computer to implicitly trust all the certificates that we issue from that authority.
Note that this opens up a security hole on your PC, because if anyone was able to get a hold of your certificate authority certificate (and its private key, with which you sign certificates), they could create certificates that your computer would silently trust. Of course, this isn't too big a deal if you just slap a nice big password on your private key, and when you're finished developing, remove the fake certificate authority certificate from your trusted certificate store.
To see what certificates you currently have on your PC, open MMC (Run->mmc.exe), click "File->Add/Remove Snap-in", select Certificates from the left list, click "Add". Select "My user account", which will mean the snapin will show certificates that are stored specifically for your Windows user account. Select Certificates from the list again and "Add" it, then this time select "Computer account". This snapin will show certificates belonging to the machine specifically, and will apply across all accounts. Press Finish, then OK. I suggest you Save this MMC arrangement, so you can get back to it more easily in the future (File->Save).
Expand "Certificates (Local Computer)\Trusted Root Certification Authorities\Certificates". This folder shows you all the Certificate Authorities that your computer trusts.
So now we need to create our own Certificate Authority certificate. Open the Visual Studio Command Prompt as Administrator. CD to some place you want to store your certificate files. Here's the command for makecert to create your certificate authority, along with an explanation of each of the options you pass to makecert:
makecert -n "CN=My Awesome Certificate Authority"
-cy authority
-a sha1
-sv "My Awesome Certificate Authority Private Key.pvk"
-r
"My Awesome Certificate Authority.cer"
-n : The certificate name. CN stands for Common Name and is the name that
identifies the certificate. For websites, this is their domain name.
-cy authority : Creates a certificate authority certificate
-a sha1 : Use the SHA1 algorithm
-sv : The private key to use, or create.
-r : Create a self-signed certificate (so that you are the root of the certificate chain)
*.cer : The filename to export to
Because you haven't created a private key before, the -sv option will create you one. Therefore, Makecert will ask you for a password that will lock the private key. Provide a nice strong one. When it then goes to use the private key, it asks you to re-provide that same password.
You can now install your new certificate authority certificate into the trusted store. To do this, simply go to your MMC console, right click on "Trusted Root Certification Authorities", go "All Tasks", then "Import". Select your new certificate, and when it asks you where to put the certificate, ensure that it goes into "Trusted Root Certification Authorities". Your computer now implicitly trusts all certificates signed by that new certificate authority.
Now we need to create a client certificate that is signed by our new certificate authority. You can do this one of two ways. The first way is to create a certificate and store it and its private key in the Windows Certificate Store (what you see in MMC). This is how you do that:
makecert -n "CN=myawesomesite.com"
-ic "My Awesome Certificate Authority.cer"
-iv "My Awesome Certificate Authority Private Key.pvk"
-a sha1
-sky exchange
-pe
-sr currentuser
-ss my
"myawesomesite.cer"
-n : The certificate name. CN stands for Common Name and is the name that
identifies the certificate. For websites, this is their domain name.
-ic : The certificate to use as the root authority
-iv : The private key of the root authority certificate
-a sha1 : Use the SHA1 algorithm
-sky exchange : Create a certificate that can do key exchange
-pe : Makes the certificate's private key exportable
-sr : The certificate store location to hold the certificate (currentuser or localmachine)
-ss : The certificate store name. my is the Personal store
*.cer : The filename to export to
It will ask you for the certificate authority's private key's password, so that it can use the private key to sign your certificate. It then will store your certificate (and its private key) in the current user's Personal store. You should be able to see it in MMC. It will also create a copy of the certificate on the hard drive.
The other way you can create the certificate is to create it and its private key as files on the hard drive. You can then combine them into a single PFX (Personal Information Exchange) file, which can be imported into your certificate store if you wish. To do this, run this makecert command:
makecert -n "CN=myawesomesite.com"
-ic "My Awesome Certificate Authority.cer"
-iv "My Awesome Certificate Authority Private Key.pvk"
-a sha1
-sky exchange
-pe
-sv "myawesomesite.com Private Key.pvk"
"myawesomesite.com.cer"
-n : The certificate name. CN stands for Common Name and is the name that
identifies the certificate. For websites, this is their domain name.
-ic : The certificate to use as the root authority
-iv : The private key of the root authority certificate
-a sha1 : Use the SHA1 algorithm
-sky exchange : Create a certificate that can do key exchange
-pe : Makes the certificate's private key exportable
-sv : The private key to use, or create.
*.cer : The filename to export to
This will ask you for a password with which to lock the new private key you are creating for this certificate. It will also ask you for the password to the certificate authority's private key. It creates your certificate on the hard drive and also the private key in a PVK file.
To combine the private key and the certificate into a PFX file, run this command (this uses pvk2pfx):
pvk2pfx -pvk "myawesomesite.com Private Key.pvk"
-spc "myawesomesite.cer"
-pfx "myawesomesite.pfx"
-pi YourPassword
-pvk : The PVK file to lock away in the PFX
-spc : The certificate to put in the PFX
-pfx : The PFX file to create
-pi : The password of the private key
This will create your PFX file, which you can import into your Personal store using MMC in a similar fashion as you did with the certificate authority certificate.
And that's it. You now have a trusted certificate authority and a certificate that is signed by that authority in your computer's store. You can now use them for development (for example, for WCF service security).
Dynamic Queries in Entity Framework using Expression Trees
June 06, 2009 2:00 PM by Daniel Chambers (last modified on January 13, 2011 12:24 PM)
Most of the queries you do in your application are probably static queries. The parameters you set on the query probably change, but the actual query itself doesn't. That's why compiled queries are so cool, because you can pre-compile and reuse a query over and over again and just vary the parameters (see my last blog for more information).
But sometimes you might need to construct a query at runtime. By this I mean not just changing the parameter values, but actually changing the query structure. A good example of this would be a filter, where, depending on what the user wants, you dynamically create a query that culls a set down to what the user is looking for. If you've only got a couple of filter options, you can probably get away with writing multiple compiled queries to cover the permutations, but it only takes a few filter options before you've got a lot of permutations and it becomes unmanageable.
A good example of this is file searching. You can filter a list of files by name, type, size, date modified, etc. The user may only want to filter by one of these filters, for example with "Awesome" as the filename. But the user may also want to filter by multiple filters, for example, "Awesome" as the filename, but modified after 2009/07/07 and more than 20MB in size. To create a static query for each permutation would result in 16 queries (4 squared)!
My first foray into creating dynamic queries is a bit less ambitious than the above example, however. I have a scenario where I need to pull out a number of Tag objects from the database by their IDs. However, the number of the Tag objects needed is determined by the user. They may select 3 Tags, or they may select 6 Tags, or they may select 4 tags; it's up to them.
The most boring approach is, of course, to get each Tag out of the database individually with its own query (the "get each Tag individually" approach):
IList<Tag> list = new List<Tag>();
foreach (int tagId in WantedTagIds)
{
int localTagId = tagId;
Tag theTag = (from tag in context.Tag
where
tag.Account.ID == AccountId &&
tag.ID == localTagId
select tag).First();
list.Add(theTag);
}
You could compile that query to make it run faster, but it's still a slow operation. If the user wants to get 6 Tags, you need to query the database 6 times. Not very cool.
This is where dynamic queries can step in. If the user asks for 3 Tags, you can generate a where clause that gets all three Tags in one go; essentially: tag.ID == 10 || tag.ID == 12 || tag.ID == 14. That way you get all three Tags in one query to the database. So, I wrote some generic type-safe code to perform exactly that: generating a where clause expression from a list of IDs so that a Tag with any of those IDs is retrieved.
To understand how I did this, you need to understand how the where clause in an LINQ expression works. It is easiest to understand if you look at the method-chain form of LINQ rather than the special C# syntax. It looks like this:
IQueryable<Tag> tags = context.Tag.AsQueryable()
.Where(tag => tag.ID == 10);
The Where method takes a parameter that looks like this: Expression<Func<Tag, bool>>. Notice how the Func delegate is wrapped in an Expression? This means that instead of creating an actual anonymous method for the Func delegate, the compiler will instead convert your lambda expression into an Expression Tree.
An Expression Tree is a representation of your expression in an object tree. Here is an object tree that shows the main objects in the expression tree generated by the compiler for the lambda expression in the above example's Where method:
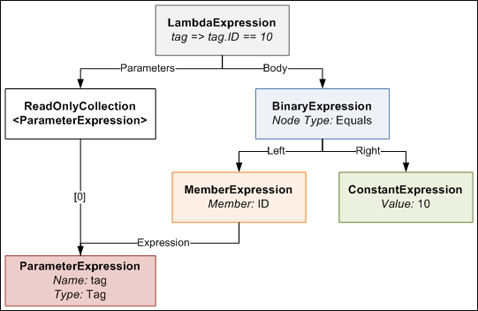
The LambdaExpression has a collection of ParameterExpressions, which are the parameters on the left side of the => symbol in the code. The actual Body of the lambda is made up of a BinaryExpression of type Equals, whose Right side is a ConstantExpression that contains the value of 10, and whose Left side is a MemberExpression. A MemberExpression represents the access of the ID property on the tag parameter.
So if we wanted to represent a more complex expression such as:
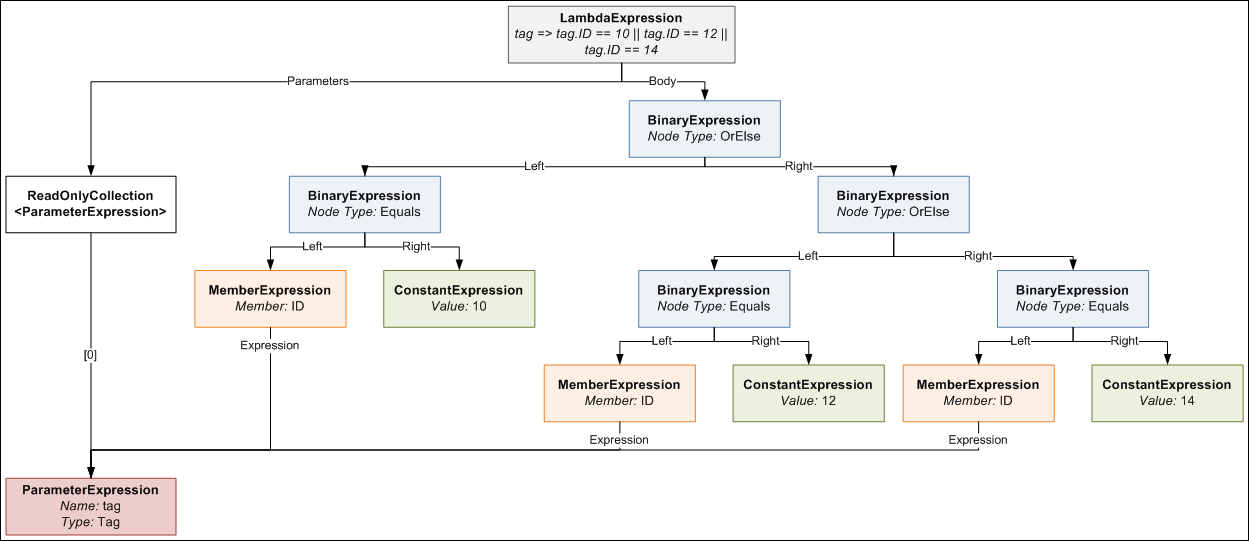
tag => tag.ID == 10 || tag.ID == 12 || tag.ID == 14
this is what the expression tree would look like. It looks a bit daunting, but computers are very good at trees, so writing code to generate such a tree is not too difficult with the help of a little recursion.
{kind=link}
I defined a special utility method that allows you to create an expression tree like the one above that results in a Where expression that accepts a particular tag so long as its ID is in a certain set of IDs. The method is generic and reusable across anywhere where you need a Where filter that gets "this value, or this value, or this value... etc". The public method looks like this:
public static Expression<Func<TValue, bool>> BuildOrExpressionTree<TValue, TCompareAgainst>(
IEnumerable<TCompareAgainst> wantedItems,
Expression<Func<TValue, TCompareAgainst>> convertBetweenTypes)
{
ParameterExpression inputParam = convertBetweenTypes.Parameters[0];
Expression binaryExpressionTree = BuildBinaryOrTree(wantedItems.GetEnumerator(), convertBetweenTypes.Body, null);
return Expression.Lambda<Func<TValue, bool>>(binaryExpressionTree, new[] { inputParam });
}
It's stuffed full of generics which makes it look more complicated than it really is. Here's how you call it:
List<int> ids = new List<int> { 10, 12, 14 };
Expression<Func<Tag, bool>> whereClause = BuildOrExpressionTree<Tag, int>(wantedTagIds, tag => tag.ID);
As I explain how it works, I suggest you keep an eye on the last expression tree diagram. The method defines two generic types, one called TValue which represents the value you are comparing, in this case the Tag class. The other generic type is called TCompareAgainst and is the type of the value you are comparing against, in this case int (because the Tag.ID property is an int).
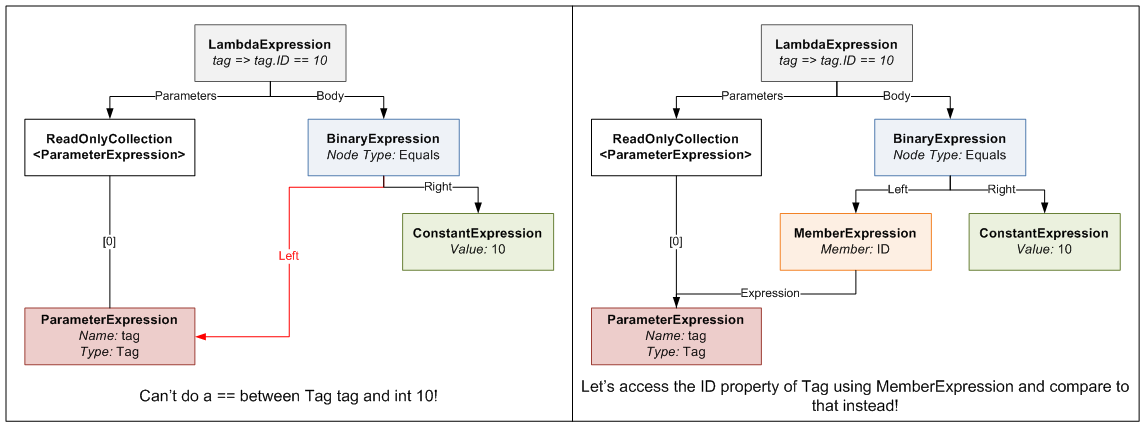
You pass the method an IEnumerable<TCompareAgainst>, which in our case is an IEnumerable<int>, because we have a list of IDs we are comparing against.
The second parameter ("convertBetweenTypes") can be a bit confusing; let me explain. The expression we are defining for the Where clause takes a Tag and returns a bool (hence the Func<Tag, bool> typed expression). Since the set of values we are comparing against are ints, we can't just do an == between the Tag and an int. To be able to do this comparison, we need to somehow "convert" the Tag we receive into an int for comparison. This is where the second parameter comes in. It defines an Expression that takes a Tag and returns an int (or in generic terms takes a TValue and returns a TCompareAgainst). When you write tag => tag.ID, the compiler generates an Expression Tree that contains a MemberExpression that accesses ID on the tag ParameterExpression. This means wherever we need to do a Tag == int, we instead do a Tag.ID == int by substituting the Tag.ID MemberExpression generated in the place of the Tag. Here's a diagram that explains what I'm ranting about.
{kind=link}
The main purpose of this method is to create the final LambdaExpression that the method returns. It does this by attaching the expression tree built by the BuildBinaryOrTree method (we'll get into this in a second) and the ParameterExpression from the convertBetweenTypes to the final LambdaExpression object.
The BuildBinaryOrTree method looks like this:
private static Expression BuildBinaryOrTree<T>(
IEnumerator<T> itemEnumerator,
Expression expressionToCompareTo,
Expression expression)
{
if (itemEnumerator.MoveNext() == false)
return expression;
ConstantExpression constant = Expression.Constant(itemEnumerator.Current, typeof(T));
BinaryExpression comparison = Expression.Equal(expressionToCompareTo, constant);
BinaryExpression newExpression;
if (expression == null)
newExpression = comparison;
else
newExpression = Expression.OrElse(expression, comparison);
return BuildBinaryOrTree(itemEnumerator, expressionToCompareTo, newExpression);
}
It takes an IEnumerator that enumerates over the wantedItems list (from the BuildOrExpressionTree method), an expression to compare each of these wanted items to (which is the compiler-generated MemberExpression from BuildOrExpressionTreeMethod), and an expression from a previous recursion (starts off as null).
The method creates an Equals BinaryExpression that compares the expressionToCompareTo and the current itemEnumerator value. It then joins this in an OrElse BinaryExpression comparison with the expression from previous recursions. It then takes this new expression and passes it down to the next recursive call. This process continues until itemEnumerator is exhausted at which point the final expression tree is returned.
Once this returned expression tree is placed in its LambdaExpression by the BuildOrExpressionTree method, you end up with a pretty expression tree like this one shown previously. We can then use this expression tree in the where clause of a LINQ method chain query.
Here's the final "generated where clause" query in action:
using (DHEntities context = new DHEntities())
{
int[] wantedTagIds = new[] {12, 24, 1, 4, 32, 19};
Expression<Func<Tag, bool>> whereClause = ExpressionTreeUtil.BuildOrExpressionTree<Tag, int>(wantedTagIds, tag => tag.ID);
IQueryable<Tag> tags = context.Tag.Where(whereClause);
IList<Tag> list = tags.ToList();
}
So how much better is this approach, which is decidedly more complex than the simple "get each Tag at a time" approach? Is it worth the effort? I performed some benchmarks similar to the ones I did in the last blog to find out.
In one benchmark run, I ran these queries, each a hundred times, each getting out the same 6 tags:
- The "get each Tag individually" query (uncompiled)
- The "get each Tag individually" query (compiled)
- The "generated where clause" query. The where clause was regenerated each time.
I then ran the benchmark 100 times so that I could get more reliable averaged values. These are the results I got:
| Average | Standard Deviation | |
|---|---|---|
| "Get Each Tag Individually" Query Loop (Uncompiled) | 3212.2ms | 40.2ms |
| "Get Each Tag Individually" Query Loop (Compiled) | 1349.3ms | 24.2ms |
| "Generated Where Clause" Query Loop | 197.8ms | 5.3ms |
As you can see, the Generated Where Clause approach is quite a lot faster than the individual queries. We can see compiling the Individual query helps, but not enough to beat the Generated Where Clause query, which is faster even though it is recompiled each time! (You can't precompile a dynamic query, obviously). The Generated Where Clause query is 6.8 times faster than the compiled Individual query and a whopping 16.2 times faster than the uncompiled Individual query.
Even though dynamic queries are lots harder than normal static queries, because you have to manually mess with Expression Trees, there are large payoffs to be had in doing so. When used in the appropriate place, dynamic queries are faster than static queries. They could also potentially make your code cleaner, especially in the case of the filter example I talked about at the beginning of this blog. So consider getting up to speed with Expression Trees. It's worth the effort.
Making Entity Framework as Quick as a Fox
June 04, 2009 2:00 PM by Daniel Chambers
Entity Framework is the new (as of .NET 3.5 SP1) ORM technology for the .NET Framework. ORM technologies are widely accepted as the "better" way of accessing relational databases, because they allow you to work with relational data as objects in the world of objects. However, ORM tech can be slower than writing manual SQL queries yourself. This can be seen in this blog that benchmarks Entity Framework versus LINQ to SQL and a manual SQLDataReader.
Hardware is cheap (compared to programmer labour, which is not) so getting a faster machine could be an effective strategy to counter performance issues with ORM. However, what if we could squeeze some extra performance out of Entity Framework with only a little effort?
This is where Compiled Queries come in. Compiled queries are good to use where you have one particular query that you use over and over again in the same application. A normal query (using LINQ) is passed to Entity Framework as an expression tree. Entity Framework translates it into a command tree that is then translated by a database-specific provider into a query against a database. It does this every time you execute the query. Obviously, if this query is in a loop (or is called often) this is suboptimal because the query is recompiled every time, even though all that's probably changed is the parameters in the query. Compiled queries ensure that the query is only compiled once, and the only thing that varies is the parameters.
I created a quick benchmark app to find out just how much faster compiled queries are against normal queries. I'll illustrate how the benchmark works and then present the results.
Basically, I had a particular non-compiled LINQ to Entities query which I ran 100 times in a loop and timed how long it took. I then created the same query, but as a compiled query instead. I ran it once, because the query is compiled the first time you run it, not when you construct it. I then ran it 100 times in a loop and timed how long it took. Also, before doing any of the above, I ran the non-compiled query once, because it seemed to take a long time for the very first operation using the Entity Framework to run, so I wanted that time excluded from my results.
The non-compiled query I ran looked like this:
IQueryable<Transaction> transactions =
from transaction in context.Transaction
where
transaction.TransactionDate >= FromDate &&
transaction.TransactionDate <= ToDate
select transaction;
List<Transaction> list = transactions.ToList();
As you can see, it's nothing fancy, just a simple query with a small where clause. This query returns 39 Transaction objects from my database (SQL Server 2005).
The compiled query was created like this:
Func<DHEntities, DateTime, DateTime, IQueryable<Transaction>>
query;
query = CompiledQuery.Compile(
(DHEntities ctx, DateTime fromD, DateTime toD) =>
from transaction in ctx.Transaction
where
transaction.TransactionDate >= fromD &&
transaction.TransactionDate <= toD
select transaction);
As you can see, to create a compiled query you pass your LINQ query to CompiledQuery.Compile() via a lambda expression that defines the things that the query needs (ie the Object Context (in this case, DHEntities) and the parameters used (in this case two DateTimes). The Compile function will return a Func delegate that has the types you defined in your lambda, plus one extra: the return type of the query (in this case IQueryable<Transaction>).
The compiled query was executed like this:
IQueryable<Transaction> transactions = query.Invoke(context, FromDate, ToDate); List<Transaction> list = transactions.ToList();
I ran the benchmark 100 times, collected all the data and then averaged the results:
| Average | Standard Deviation | |
|---|---|---|
| Non-compiled Query Loop | 534.1ms | 20.6ms |
| Compiled Query Loop | 63.1ms | 0.6ms |
The results are impressive. In this case, compiled queries are 8.5 times faster than normal queries! I've showed the standard deviation so that you can see that the results didn't fluctuate much between each benchmark run.
The use case I have for using compiled queries is doing database access in a WCF service. I expose a service that will likely be beaten to death by constant queries from an ASP.NET MVC webserver. Sure, I could get larger hardware to make the WCF service go faster, or I could simply get a rather massive performance boost just by using compiled queries.
Sexy C# Filter Code for RealDWG Database Navigation
May 31, 2009 2:00 PM by Daniel Chambers
I've been having to use RealDWG for my part time programming work at Onset to programmatically read DWG files (AutoCAD drawing files). I've been finding RealDWG a pain to learn, as AutoDesk's documentation seems to assume you're an in-house AutoCAD programmer, so they blast you with all these low level file access details like BlockTables and SymbolTables. However, this isn't surprising, since I believe AutoDesk eat their own dog food and use the same API internally. That doesn't make it any easier to learn and use, though.
RealDWG (or ObjectARX, which is the underlying API that is wrapped with .NET wrapper classes) reads a DWG file into an internal "database". Everything is basically an ObjectId, which is a short stub object that you give to a Transaction object that will get you the actual real object. Objects are nested inside objects, which are nested inside more objects, and none of it typesafe, as Transaction returns objects as their top level DBObject class. So you're constantly casting to the actual concrete type you want. Casting all over the place == bad.
Anyway, I found that navigating around a RealDWG object graph was a pain. For example, to find BlockTableRecords (which are inside a BlockTable) that contain AttributeDefinitions (don't worry about what those are; it's not important) you need to do something like this:
BlockTable blockTable = (BlockTable)transaction.GetObject(db.BlockTableId, OpenMode.ForRead);
foreach (ObjectId objectId in blockTable)
{
DBObject dbObject = transaction.GetObject(objectId, OpenMode.ForRead);
BlockTableRecord record = (BlockTableRecord)dbObject;
if (record.HasAttributeDefinitions == false)
continue;
//Do what you need to here...
}
That's really verbose and messy, with a lot of code just dedicated to opening objects and casting them, and filtering. It was annoying me, so I refactored it and wrote the following sexy method that uses generics with delegates to clean that right up:
private IEnumerable<T> Filter<T>(Predicate<T> predicate, IEnumerable realDwgEnumerable, Transaction transaction)
where T : class
{
foreach (ObjectId obj in realDwgEnumerable)
{
DBObject dbObject = transaction.GetObject(obj, OpenMode.ForRead);
T genericObj = dbObject as T;
if (genericObj == null)
continue;
if (predicate != null && predicate(genericObj) == false)
continue;
yield return genericObj;
}
}
The method is generic and takes an IEnumerable (which is the non-generic interface that all the RealDWG stuff that you can iterate over implements) and a Transaction (to open objects from ObjectId stubs with). Additionally, it takes a Predicate<T> that allows you to specify a condition on which concrete objects are included in the final set. It returns an IEnumerable of the generic type T.
What the method will do is iterate over the IEnumerable and pull out all the objects that match the generic type that you define when you call the method. Additionally, it will return only those objects that match your predicate. The method uses the yield return keywords to lazy return results as the returned IEnumerable is iterated over.
Here's the above messy example all sexed up by using this method:
BlockTable blockTable = (BlockTable)transaction.GetObject(db.BlockTableId, OpenMode.ForRead);
IEnumerable<BlockTableRecord> blockTableRecords = Filter<BlockTableRecord>(btr => btr.HasAttributeDefinitions, blockTable, transaction);
foreach (BlockTableRecord blockTableRecord in blockTableRecords)
{
//Do what you need to here...
}
Just like using LINQ, the above snippet (which looks longer than it really is thanks to wrapping) simply declares that it wants all BlockTableRecords in the BlockTable that have attribute definitions (using a lambda expression). It's much neater, if only because it shifts the filtering code out of the way into the Filter method, so that it doesn't clutter up what I'm trying to do. It also makes the foreach type-safe, because now we're iterating over an IEnumerable<T> rather than a non-generic IEnumerable. Worst case: the IEnumerable<T> is empty. No InvalidCastExceptions here.
Another place where this method is awesome is when you've got lots of different typed objects getting returned as you iterate over the RealDWG IEnumerable object, which happens a lot. Using this method you can very simply get the type of object you're looking for by doing this:
IEnumerable<TypeIWant> objectsIWant = Filter<TypeIWant>(null, blockTableRecord, transaction);
Optimally you use the overload that doesn't include the Predicate<T> as a parameter, instead of passing null as the predicate (the overload passes null for you). I didn't show that here, but it's in my code.
Wrapping up, this again confirms how much I love C# 3.0 (and soon 4.0!). All the new language features let you do some simply awesome things that you just can't do in aging languages like Java (Java doesn't even have delegates, let alone lambda expressions!).