
Only showing posts tagged with "Entity Framework"
More Lessons from the LINQ Database Query Performance Land
July 19, 2011 2:00 PM by Daniel Chambers (last modified on July 19, 2011 2:20 PM)
Writing LINQ against databases using providers like LINQ to SQL and Entity Framework is harder than it first appears. There are many different ways to write the same query in LINQ and many of them cause LINQ providers to generate really horrible SQL. LINQ to SQL is quite the offender in this area but, as we’ll see, Entity Framework can write bad SQL too. The trick is knowing how to write LINQ that doesn’t result in horribly slow queries, so in this blog post we’ll look at an interesting table joining scenario where different LINQ queries produce SQL of vastly different quality.
Here’s the database schema:
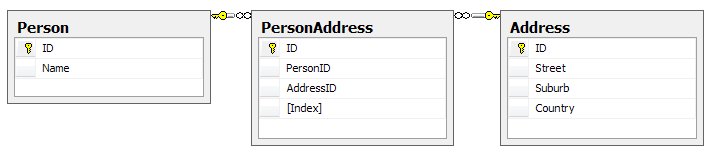
Yes, this may not be the best database design as you could arguably merge PersonAddress and Address, but it’ll do for an example; it’s the query structure we’re more interested in rather than the contents of the tables. One thing to note is that the Index column on PersonAddress is there to number the addresses associated with the person, ie Address 1, Address 2. There cannot be two PersonAddresses for the same person with the same Index. Our entity classes map exactly to these tables.
Let’s say we want to write a query for reporting purposes that flattens this structure out like so:

Optimally, we’d like the LINQ query to write this SQL for us (or at least SQL that performs as well as this; this has a cost of 0.0172):
SELECT p.Name, a1.Street AS 'Street 1', a1.Suburb AS 'Suburb 1', a1.Country AS 'Country 1',
a2.Street AS 'Street 2', a2.Suburb AS 'Suburb 2', a2.Country AS 'Country 2'
FROM Person p
LEFT OUTER JOIN PersonAddress pa1 on p.ID = pa1.PersonID AND pa1.[Index] = 1
LEFT OUTER JOIN PersonAddress pa2 on p.ID = pa2.PersonID AND pa2.[Index] = 2
LEFT OUTER JOIN [Address] a1 on a1.ID = pa1.AddressID
LEFT OUTER JOIN [Address] a2 on a2.ID = pa2.AddressID
One way of doing this using LINQ, and taking advantage of navigation properties on the entity classes, might be this:
from person in context.People
let firstAddress = person.PersonAddresses.FirstOrDefault(pa => pa.Index == 1).Address
let secondAddress = person.PersonAddresses.FirstOrDefault(pa => pa.Index == 2).Address
select new
{
Name = person.Name,
Street1 = firstAddress.Street,
Suburb1 = firstAddress.Suburb,
Country1 = firstAddress.Country,
Street2 = secondAddress.Street,
Suburb2 = secondAddress.Suburb,
Country2 = secondAddress.Country,
}
However, using LINQ to SQL, the following SQL is generated (and its cost is 0.0458, which is nearly three times the cost of the SQL we’re aiming for):
SELECT [t0].[Name], (
SELECT [t3].[Street]
FROM (
SELECT TOP (1) [t1].[AddressID] FROM [PersonAddress] AS [t1]
WHERE ([t1].[Index] = 1) AND ([t1].[PersonID] = [t0].[ID])
) AS [t2]
INNER JOIN [Address] AS [t3] ON [t3].[ID] = [t2].[AddressID]
) AS [Street1], (
SELECT [t6].[Suburb]
FROM (
SELECT TOP (1) [t4].[AddressID] FROM [PersonAddress] AS [t4]
WHERE ([t4].[Index] = 1) AND ([t4].[PersonID] = [t0].[ID])
) AS [t5]
INNER JOIN [Address] AS [t6] ON [t6].[ID] = [t5].[AddressID]
) AS [Suburb1], (
SELECT [t9].[Country]
FROM (
SELECT TOP (1) [t7].[AddressID] FROM [PersonAddress] AS [t7]
WHERE ([t7].[Index] = 1) AND ([t7].[PersonID] = [t0].[ID])
) AS [t8]
INNER JOIN [Address] AS [t9] ON [t9].[ID] = [t8].[AddressID]
) AS [Country1], (
SELECT [t12].[Street]
FROM (
SELECT TOP (1) [t10].[AddressID] FROM [PersonAddress] AS [t10]
WHERE ([t10].[Index] = 2) AND ([t10].[PersonID] = [t0].[ID])
) AS [t11]
INNER JOIN [Address] AS [t12] ON [t12].[ID] = [t11].[AddressID]
) AS [Street2], (
SELECT [t15].[Suburb]
FROM (
SELECT TOP (1) [t13].[AddressID] FROM [PersonAddress] AS [t13]
WHERE ([t13].[Index] = 2) AND ([t13].[PersonID] = [t0].[ID])
) AS [t14]
INNER JOIN [Address] AS [t15] ON [t15].[ID] = [t14].[AddressID]
) AS [Suburb2], (
SELECT [t18].[Country]
FROM (
SELECT TOP (1) [t16].[AddressID] FROM [PersonAddress] AS [t16]
WHERE ([t16].[Index] = 2) AND ([t16].[PersonID] = [t0].[ID])
) AS [t17]
INNER JOIN [Address] AS [t18] ON [t18].[ID] = [t17].[AddressID]
) AS [Country2]
FROM [Person] AS [t0]
Hoo boy, that’s horrible SQL! Notice how it’s doing a whole table join for every column? Imagine how that query would scale the more columns you had in your LINQ query! Epic fail.
Entity Framework (v4) fares much better, writing a ugly duckling query that is actually beautiful inside, performing at around the same speed as the target SQL (0.0172):
SELECT [Extent1].[ID] AS [ID], [Extent1].[Name] AS [Name], [Extent3].[Street] AS [Street],
[Extent3].[Suburb] AS [Suburb], [Extent3].[Country] AS [Country], [Extent5].[Street] AS [Street1],
[Extent5].[Suburb] AS [Suburb1], [Extent5].[Country] AS [Country1]
FROM [dbo].[Person] AS [Extent1]
OUTER APPLY (
SELECT TOP (1) [Extent2].[PersonID] AS [PersonID], [Extent2].[AddressID] AS [AddressID],
[Extent2].[Index] AS [Index]
FROM [dbo].[PersonAddress] AS [Extent2]
WHERE ([Extent1].[ID] = [Extent2].[PersonID]) AND (1 = [Extent2].[Index]) ) AS [Element1]
LEFT OUTER JOIN [dbo].[Address] AS [Extent3] ON [Element1].[AddressID] = [Extent3].[ID]
OUTER APPLY (
SELECT TOP (1) [Extent4].[PersonID] AS [PersonID], [Extent4].[AddressID] AS [AddressID],
[Extent4].[Index] AS [Index]
FROM [dbo].[PersonAddress] AS [Extent4]
WHERE ([Extent1].[ID] = [Extent4].[PersonID]) AND (2 = [Extent4].[Index]) ) AS [Element2]
LEFT OUTER JOIN [dbo].[Address] AS [Extent5] ON [Element2].[AddressID] = [Extent5].[ID]
So, if we’re stuck using LINQ to SQL and can’t jump ship to the more mature Entity Framework, how can we manipulate the LINQ to force it to write better SQL? Let’s try putting the Index predicate (ie pa => pa.Index == 1) into the join instead:
from person in context.Persons
join pa in context.PersonAddresses on new { person.ID, Index = 1 } equals new { ID = pa.PersonID, pa.Index } into pa1s
join pa in context.PersonAddresses on new { person.ID, Index = 2 } equals new { ID = pa.PersonID, pa.Index } into pa2s
from pa1 in pa1s.DefaultIfEmpty()
from pa2 in pa2s.DefaultIfEmpty()
let firstAddress = pa1.Address
let secondAddress = pa2.Address
select new
{
Name = person.Name,
Street1 = firstAddress.Street,
Suburb1 = firstAddress.Suburb,
Country1 = firstAddress.Country,
Street2 = secondAddress.Street,
Suburb2 = secondAddress.Suburb,
Country2 = secondAddress.Country,
}
This causes LINQ to SQL (and Entity Framework) to generate exactly the SQL we were originally aiming for! Notice the use of DefaultIfEmpty to turn the joins into left outer joins (remember that joins in LINQ are inner joins).
At this point you may be thinking “I’ll just use Entity Framework because it seems like I can trust it to write good SQL for me”. Hold your horses my friend; let’s modify the above query just slightly and get rid of those let statements, inlining the navigation through PeopleAddress’s Address property. That’s just navigating through a many to one relation, that shouldn’t cause any problems, right?
from person in context.Persons
join pa in context.PersonAddresses on new { person.ID, Index = 1 } equals new { ID = pa.PersonID, pa.Index } into pa1s
join pa in context.PersonAddresses on new { person.ID, Index = 2 } equals new { ID = pa.PersonID, pa.Index } into pa2s
from pa1 in pa1s.DefaultIfEmpty()
from pa2 in pa2s.DefaultIfEmpty()
select new
{
Name = person.Name,
Street1 = pa1.Address.Street,
Suburb1 = pa1.Address.Suburb,
Country1 = pa1.Address.Country,
Street2 = pa2.Address.Street,
Suburb2 = pa2.Address.Suburb,
Country2 = pa2.Address.Country,
}
Wrong! Now Entity Framework is doing that retarded table join-per-column thing (the query cost is 0.0312):
SELECT [Extent1].[ID] AS [ID], [Extent1].[Name] AS [Name], [Extent4].[Street] AS [Street],
[Extent5].[Suburb] AS [Suburb], [Extent6].[Country] AS [Country], [Extent7].[Street] AS [Street1],
[Extent8].[Suburb] AS [Suburb1], [Extent9].[Country] AS [Country1]
FROM [dbo].[Person] AS [Extent1]
LEFT OUTER JOIN [dbo].[PersonAddress] AS [Extent2] ON ([Extent1].[ID] = [Extent2].[PersonID]) AND (1 = [Extent2].[Index])
LEFT OUTER JOIN [dbo].[PersonAddress] AS [Extent3] ON ([Extent1].[ID] = [Extent3].[PersonID]) AND (2 = [Extent3].[Index])
LEFT OUTER JOIN [dbo].[Address] AS [Extent4] ON [Extent2].[AddressID] = [Extent4].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent5] ON [Extent2].[AddressID] = [Extent5].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent6] ON [Extent2].[AddressID] = [Extent6].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent7] ON [Extent3].[AddressID] = [Extent7].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent8] ON [Extent3].[AddressID] = [Extent8].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent9] ON [Extent3].[AddressID] = [Extent9].[ID]
Incidentally, if you put that query through LINQ to SQL, you’ll find it can deal with the inlined navigation properties and it still generates the correct query (sigh!).
So what’s the lesson here? The lesson is that you must always keep a very close eye on what SQL your LINQ providers are writing for you. A tool like LINQPad may be of some use, as you can write your queries in it and it’ll show you the generated SQL. Although Entity Framework does a better job with SQL generation than LINQ to SQL, as evidenced by it being able to handle our first, more intuitive, LINQ query, it’s still fairly easy to trip it up and get it to write badly performing SQL, so you still must keep your eye on it.
Performing Date & Time Arithmetic Queries using Entity Framework v1
June 07, 2010 3:21 PM by Daniel Chambers (last modified on June 09, 2010 2:58 AM)
If one is writing legacy code in .NET 3.5 SP1’s Entity Framework v1 (yes, your brand new code has now been put into the legacy category by .NET 4 :( ), one will find a severe lack of any date & time arithmetic ability. If you look at LINQ to Entities, you will see no date & time arithmetic methods are recognised. And if you look at the canonical functions that Entity SQL provides, you will notice a severe lack of any date & time arithmetic functions. Thankfully, this strangely missing functionality in canonical ESQL has been resolved as of .NET 4; however, that doesn’t help those of us who haven’t yet upgraded to Visual Studio 2010! Thankfully, all is not lost: there is a solution that only sucks a little bit.
Date & time arithmetic is a pretty necessary ability. Imagine the following simplified scenario, where one has a “Contract” entity that defines a business contract that starts at a certain date and lasts for a duration:

Imagine that you need to perform a query that finds all Contracts that were active on a specific date. You may think of performing a LINQ to Entities query that looks like this:
IQueryable<Contract> contracts =
from contract in Contracts
where activeOnDate >= contract.StartDate &&
activeOnDate < contract.StartDate.AddMonths(contract.Duration)
select contract
However, this is not supported by LINQ to Entities and you’ll get a NotSupportedException. With canonical ESQL missing any defined date & time arithmetic functions, it seems we are left without a recourse.
However, if one digs around in MSDN, one may stumble across the fact that the SQL Server Entity Framework provider defines some provider-specific ESQL functions with which one can use to do date & time arithmetic. So we can write an ESQL query to get the functionality we wish:
const string eSqlQuery = @"SELECT VALUE c FROM Contracts AS c
WHERE @activeOnDate >= c.StartDate
AND @activeOnDate < SqlServer.DATEADD('months', c.Duration, c.StartDate)";
ObjectQuery<Contract> contracts =
context.CreateQuery<Contract>(eSqlQuery, new ObjectParameter("activeOnDate", activeOnDate));
Note the use of the SqlServer.DATEADD ESQL function. The “SqlServer” bit is specifying the SQL Server provider’s specific namespace. Obviously this approach has some disadvantages: it’s not as nice as using LINQ to Entities, and it’s also not database provider agnostic (so if you’re using Oracle you’ll need to see whether your Oracle provider has something like this). However, the alternatives are either to write SQL manually (negating the usefulness of Entity Framework) or to download all the entities into local memory and use LINQ to Objects (almost never, ever an acceptable option!).
Notice that using the CreateQuery function to create the query from ESQL returned an ObjectQuery<T> (which implements IQueryable<T>)? This means that you can now use LINQ to Entities to change that query. For example, what if we wanted to perform some further filtering that can be customised by the user (the user’s filtering preferences are set in the ContractFilterSettings class in the below example):
private ObjectQuery<Contract> CreateFilterSettingsAsQueryable(ContractFilterSettings filterSettings, MyEntitiesContext context)
{
IQueryable<Contract> query = context.Contracts;
if (filterSettings.ActiveOnDate != null)
{
const string eSqlQuery = @"SELECT VALUE c FROM Contracts AS c
WHERE @activeOnDate >= c.StartDate
AND @activeOnDate < SqlServer.DATEADD('months', c.Duration, c.StartDate)";
query = context.CreateQuery<Contract>(eSqlQuery, new ObjectParameter("activeOnDate", filterSettings.ActiveOnDate));
}
if (filterSettings.SiteId != null)
query = query.Where(c => c.SiteID == filterSettings.SiteId);
if (filterSettings.ContractNumber != null)
query = query.Where(c => c.ContractNumber == filterSettings.ContractNumber);
return (ObjectQuery<Contract>)query;
}
Being able to continue to use LINQ to Entities after creating the initial query in ESQL means that you can have the best of both worlds (forgetting the fact that we ought to be able to do date & time arithmetic in LINQ to Entities in the first place!). Note that although you can start a query in ESQL and then add to it with LINQ to Entities, you cannot start a query in LINQ to Entities and add to it with ESQL, hence why the ActiveOnDate filter setting was done first.
For those who use .NET 4, unfortunately you’re still stuck with being unable to do date & time arithmetic with LINQ to Entities by default (Alex James told me on Twitter a while back that this was purely because of time constraints, not because they are evil or something :) ). However, you get canonical ESQL functions that are provider independent (so instead of using SqlServer.DATEADD above, you’d use AddMonths). If you really want to use LINQ to Entities (which is not surprising at all), you can create ESQL snippets in your model (“Model Defined Functions”) and then create annotated method stubs which Entity Framework will recognise when you use them inside a LINQ to Entities query expression tree. For more information see this post on the Entity Framework Design blog, and this MSDN article.
EDIT: Diego Vega kindly pointed out to me on Twitter that, in fact, Entity Framework 4 comes with some methods you can mix into your LINQ to Entities queries to call on EF v4’s new canonical date & time ESQL functions. Those methods (as well as a bunch of others) can be found in the EntityFunctions class as static methods. Thanks Diego!
DigitallyCreated Utilities v1.0.0 Released
March 24, 2010 2:43 PM by Daniel Chambers (last modified on June 07, 2010 3:35 PM)
After a hell of a lot of work, I am happy to announce that the 1.0.0 version of DigitallyCreated Utilities has been released! DigitallyCreated Utilities is a collection of many neat reusable utilities for lots of different .NET technologies that I’ve developed over time and personally use on this website, as well as on others I have a hand in developing. It’s a fully open source project, licenced under the Ms-PL licence, which means you can pretty much use it wherever you want and do whatever you want to it. No viral licences here.
The main reason that it has taken me so long to release this version is because I’ve been working hard to get all the wiki documentation on CodePlex up to scratch. After all, two of the project values are:
- To provide fully XML-documented source code
- To back up the source code documentation with useful tutorial articles that help developers use this project
And truly, nothing is more frustrating than code with bad documentation. To me, bad documentation is the lack of a unifying tutorial that shows the functionality in action, and the lack of decent XML documentation on the code. Sorry, XMLdoc that’s autogenerated by tools like GhostDoc, and never added to by the author, just doesn’t cut it. If you can auto-generate the documentation from the method and parameter names, it’s obviously not providing any extra value above and beyond what was already there without it!
So what does DCU v1.0.0 bring to the table? A hell of a lot actually, though you may not need all of it for every project. Here’s the feature list grouped by broad technology area:
- ASP.NET MVC and LINQ
- Sorting and paging of data in a table made easy by HtmlHelpers and LINQ extensions (see tutorial)
- ASP.NET MVC
- HtmlHelpers
- TempInfoBox - A temporary "action performed" box that displays to the user for 5 seconds then fades out (see tutorial)
- CollapsibleFieldset - A fieldset that collapses and expands when you click the legend (see tutorial)
- Gravatar - Renders an img tag for a Gravatar (see tutorial)
- CheckboxStandard & BoolBinder - Renders a normal checkbox without MVC's normal hidden field (see tutorial)
- EncodeAndInsertBrsAndLinks - Great for the display of user input, this will insert <br/>s for newlines and <a> tags for URLs and escape all HTML (see tutorial)
- IncomingRequestRouteConstraint - Great for supporting old permalink URLs using ASP.NET routing (see tutorial)
- Improved JsonResult - Replaces ASP.NET MVC's JsonResult with one that lets you specify JavaScriptConverters (see tutorial)
- Permanently Redirect ActionResults - Redirect users with 301 (Moved Permanently) HTTP status codes (see tutorial)
- Miscellaneous Route Helpers - For example, RouteToCurrentPage (see tutorial)
- HtmlHelpers
- LINQ
- MatchUp & Federator LINQ methods - Great for doing diffs on sequences (see tutorial)
- Entity Framework
- CompiledQueryReplicator - Manage your compiled queries such that you don't accidentally bake in the wrong MergeOption and create a difficult to discover bug (see tutorial)
- Miscellaneous Entity Framework Utilities - For example, ClearNonScalarProperties and Setting Entity Properties to Modified State (see tutorial)
- Error Reporting
- Easily wire up some simple classes and have your application email you detailed exception and error object dumps (see tutorial)
- Concurrent Programming
- Unity & WCF
- WCF Client Injection Extension - Easily use dependency injection to transparently inject WCF clients using Unity (see tutorial)
- Miscellaneous Base Class Library Utilities
- SafeUsingBlock and DisposableWrapper - Work with IDisposables in an easier fashion and avoid the bug where using blocks can silently swallow exceptions (see tutorial)
- Time Utilities - For example, TimeSpan To Ago String, TzId -> Windows TimeZoneInfo (see tutorial)
- Miscellaneous Utilities - Collection Add/RemoveAll, Base64StreamReader, AggregateException (see tutorial)
DCU is split across six different assemblies so that developers can pick and choose the stuff they want and not take unnecessary dependencies if they don’t have to. This means if you don’t use Unity in your application, you don’t need to take a dependency on Unity just to use the Error Reporting functionality.
I’m really pleased about this release as it’s the culmination of rather a lot of work on my part that I think will help other developers write their applications more easily. I’m already using it here on DigitallyCreated in many many places; for example the Error Reporting code tells me when this site crashes (and has been invaluable so far), the CompiledQueryReplicator helps me use compiled queries effectively on the back-end, and the ReaderWriterLock is used behind the scenes for the Twitter feed on the front page.
I hope you enjoy this release and find some use for it in your work or play activities. You can download it here.
Entity Framework, TransactionScope and MSDTC
January 01, 2010 2:00 AM by Daniel Chambers (last modified on June 16, 2011 2:05 PM)
Update: Please note that the behaviour described in this article only occurs when using SQL Server 2005. SQL Server 2008 (and .NET 3.5+) can handle multiple connections within a transaction without requiring MSDTC promotion.
I've been tightening up code on a website I'm writing for work, and as such I've been improving the transactional integrity of some of the code that talks to our database (written using Entity Framework). Namely, I've been using TransactionScope to create transactions at specific isolation levels to ensure that no weird concurrency issues can slip in.
TransactionScope is very powerful. It has the ability to maintain your transaction across two (or more) database connections (or at least the SQL Server database code that uses it does) or even after you close the connection to the database. This is done by promoting your transaction up to being a "distributed transaction" that is managed by the Microsoft Distributed Transaction Coordinator (MSDTC) when you start to use multiple connections, or close the connection that you currently have a transaction in. So, essentially, as soon as your transaction becomes something that SQL Server can't handle with its normal transaction, the transaction is palmed off to MSDTC to manage.
An MSDTC transaction comes at a performance price as the transaction is no longer a lightweight transaction managed by SQL Server internally, but a heavyweight MSDTC transaction that is much more powerful. So, if at all possible, we do not want to use MSDTC (unless, of course, we actually need it).
However, there is a funny (or not so funny, when you think about it) behaviour that Entity Framework exhibits that causes your innocent transaction to be promoted to being an MSDTC transaction. Consider this code:
using (TestDBEntitiesContext context = new TestDBEntitiesContext())
{
using (TransactionScope transaction = new TransactionScope())
{
var authors = (from author in context.Authors
select author).ToList();
int count = (from author in context.Authors
select author).Count();
transaction.Complete();
}
}
This looks like a pretty innocent bit of code and looks like it should not result in transaction promotion. By putting the lifetime of the transaction (its using block) inside the lifetime of the ObjectContext, we ensure that the transaction cannot outlive any connection used by the context and therefore cause a promotion to an MSDTC transaction.
However, this code causes a transaction promotion on line 8. You can see this by ensuring the MSDTC service ("Distributed Transaction Coordinator") is stopped and then waiting for the exception that will be thrown because the SqlConnection is unable to promote the transaction since MSDTC is not running.
Why does this occur? A bit of digging on MSDN comes up with this bit of innocuous documentation:
Promotion of a transaction to a DTC may occur when a connection is closed and reopened within a single transaction. Because Object Services opens and closes the connection automatically, you should consider manually opening and closing the connection to avoid transaction promotion.
By sticking some breakpoints in the code above, we can observe this behaviour in action. The connection (ObjectContext.Connection) is closed by default, is opened quickly for the first query then closed immediately, then opened again for the second query, then closed. This second connection that is opened causes the transaction promotion!
At first glance this seemed to me to be an inefficient way of handling the connection! It's not that uncommon that one would want to do more than one thing with the ObjectContext in sequence and having a connection opened and closed for each query seems really inefficient.
However, upon further thought, I realised the reason why the Entity Framework team does this is probably to cover the use case where you have a long-lived ObjectContext (unlike here where we create it quickly, use it, and then throw it away). If the ObjectContext is going to be around for a long time (perhaps you've got one hanging around supplying data to a WPF dialog) we don't want it to hog a connection for all that time (99% of the time it will be idling waiting for the user!).
However, this "feature" gets in our way when using the ObjectContext in the manner above. To change this behaviour you need to sack the ObjectContext from the connection management job and do it yourself:
using (TestDBEntitiesContext context = new TestDBEntitiesContext())
{
using (TransactionScope transaction = new TransactionScope())
{
context.Connection.Open();
var authors = (from author in context.Authors
select author).ToList();
int count = (from author in context.Authors
select author).Count();
transaction.Complete();
}
}
Notice on line 5 above we are now manually opening the connection ourselves. This ensures that the connection will be open for the duration of both our queries and will be closed when the ObjectContext goes out of scope at the end of its using block.
Using this technique we can avoid the accidental promotion of our lightweight database transaction to an heavy MSDTC transaction and thereby scrape back some lost performance.
Speeding up .NET Reflection with Code Generation
December 20, 2009 2:00 PM by Daniel Chambers
One of the bugbears I have with Entity Framework in .NET is that when you use it behind a method in the business layer (think AddAuthor(Author author)) you need to manually wipe non-scalar properties when adding entities. I define non-scalar properties as:
- EntityCollections: the "many" ends of relationships (think Author.Books)
- The single end of relationships (think Book.Author)
- Properties that participate in the Entity Key (primary key properties) (think Author.ID). These need to be wiped as the database will automatically fill them (identity columns in SQL Server)
If you don't wipe the relationship properties when you add the entity object you get an UpdateException when you try to SaveChanges on the ObjectContext.
You can't assume that someone calling your method knows about this Entity Framework behaviour, so I consider it good practice to wipe the properties for them so they don't see unexpected UpdateExceptions floating up from the business layer. Obviously, having to write
author.ID = default(int); author.Books.Clear();
is no fun (especially on entities that have more properties than this!). So I wrote a method that you can pass an EntityObject to and it will wipe all non-scalar properties for you using reflection. This means that it doesn't need to know about your specific entity type until you call it, so you can use whatever entity classes you have for your project with it. However, calling methods dynamically is really slow. There will probably be lots faster ways of doing it in .NET 4.0 because of the DLR, but for us still back here in 3.5-land it is still slow.
So how can we enjoy the benefits of reflection but without the performance cost? Code generation at runtime, that's how! Instead of using reflection and dynamically calling methods and setting properties, we can instead use reflection once, create a new class at runtime that is able to wipe the non-scalar properties and then reuse this class over and over. How do we do this? With the System.CodeDom API, that's how (maybe in .NET 4.0 you could use the expanded Expression Trees functionality). The CodeDom API allows you to literally write code at runtime and have it compiled and loaded for you.
The following code I will go through is available as a part of DigitallyCreated Utilities open source libraries (see the DigitallyCreated.Utilities.Linq.EfUtil.ClearNonScalarProperties() method).
What I have done is create an interface called IEntityPropertyClearer that has a method that takes an object and wipes the non-scalar properties on it. Classes that implement this interface are able to wipe a single type of entity (EntityType).
public interface IEntityPropertyClearer
{
Type EntityType { get; }
void Clear(object entity);
}
I then have a helper abstract class that makes this interface easy to implement by the code generation logic by providing a type-safe method (ClearEntity) to implement and by doing some boilerplate generic magic for the EntityType property and casting in Clear:
public abstract class AbstractEntityPropertyClearer<TEntity> : IEntityPropertyClearer
where TEntity : EntityObject
{
public Type EntityType
{
get { return typeof(TEntity); }
}
public void Clear(object entity)
{
if (entity is TEntity)
ClearEntity((TEntity)entity);
}
protected abstract void ClearEntity(TEntity entity);
}
So the aim is to create a class at runtime that inherits from AbstractEntityPropertyClearer and implements the ClearEntity method so that it can clear a particular entity type. I have a method that we will now implement:
private static IEntityPropertyClearer GeneratePropertyClearer(EntityObject entity)
{
Type entityType = entity.GetType();
...
}
So the first thing we need to do is to create a "CodeCompileUnit" to put all the code we are generating into:
CodeCompileUnit compileUnit = new CodeCompileUnit(); compileUnit.ReferencedAssemblies.Add(typeof(System.ComponentModel.INotifyPropertyChanging).Assembly.Location); //System.dll compileUnit.ReferencedAssemblies.Add(typeof(EfUtil).Assembly.Location); compileUnit.ReferencedAssemblies.Add(typeof(EntityObject).Assembly.Location); compileUnit.ReferencedAssemblies.Add(entityType.Assembly.Location);
Note that we get the path to the assemblies we want to reference from the actual types that we need. I think this is a good approach as it means we don't need to hardcode the paths to the assemblies (maybe they will move in the future?).
We then need to create the class that will inherit from AbstractEntityPropertyClearer and the namespace in which this class will reside:
//Create the namespace
string namespaceName = typeof(EfUtil).Namespace + ".CodeGen";
CodeNamespace codeGenNamespace = new CodeNamespace(namespaceName);
compileUnit.Namespaces.Add(codeGenNamespace);
//Create the class
string genTypeName = entityType.FullName.Replace('.', '_') + "PropertyClearer";
CodeTypeDeclaration genClass = new CodeTypeDeclaration(genTypeName);
genClass.IsClass = true;
codeGenNamespace.Types.Add(genClass);
Type baseType = typeof(AbstractEntityPropertyClearer<>).MakeGenericType(entityType);
genClass.BaseTypes.Add(new CodeTypeReference(baseType));
The namespace we create is the namespace of the utility class + ".CodeGen". The class's name is the entity's full name (including namespace) where all "."s are replaced with "_"s and PropertyClearer appended to it (this will stop name collision). The class that the generated class will inherit from is AbstractEntityPropertyClearer but with the generic type set to be the type of entity we are dealing with (ie if the method was called with an Author, the type would be AbstractEntityPropertyClearer<Author>).
We now need to create the ClearEntity method that will go inside this class:
CodeMemberMethod clearEntityMethod = new CodeMemberMethod(); genClass.Members.Add(clearEntityMethod); clearEntityMethod.Name = "ClearEntity"; clearEntityMethod.ReturnType = new CodeTypeReference(typeof(void)); clearEntityMethod.Parameters.Add(new CodeParameterDeclarationExpression(entityType, "entity")); clearEntityMethod.Attributes = MemberAttributes.Override | MemberAttributes.Family;
Counterintuitively (for C# developers, anyway), "protected" scope is called MemberAttributes.Family in CodeDom.
We now need to find all EntityCollection properties on our entity type so that we can generate code to wipe them. We can do that with a smattering of LINQ against the reflection API:
IEnumerable<PropertyInfo> entityCollections =
from property in entityType.GetProperties()
where
property.PropertyType.IsGenericType &&
property.PropertyType.IsGenericTypeDefinition == false &&
property.PropertyType.GetGenericTypeDefinition() ==
typeof(EntityCollection<>)
select property;
We now need to generate statements inside our generated method to call Clear() on each of these properties:
foreach (PropertyInfo propertyInfo in entityCollections)
{
CodePropertyReferenceExpression propertyReferenceExpression = new CodePropertyReferenceExpression(new CodeArgumentReferenceExpression("entity"), propertyInfo.Name);
clearEntityMethod.Statements.Add(new CodeMethodInvokeExpression(propertyReferenceExpression, "Clear"));
}
On line 3 above we create a CodePropertyReferenceExpression that refers to the property on the "entity" variable which is an argument that we defined for the generated method. We then add to the method an expression that invokes the Clear method on this property reference (line 4). This will give us statements like entity.Books.Clear() (where entity is an Author).
We now need to find all the single-end-of-a-relationship properties (like book.Author) and entity key properties (like author.ID). Again, we use some LINQ to achieve this:
//Find all single multiplicity relation ends
IEnumerable<PropertyInfo> relationSingleEndProperties =
from property in entityType.GetProperties()
from attribute in property.GetCustomAttributes(typeof(EdmRelationshipNavigationPropertyAttribute), true).Cast<EdmRelationshipNavigationPropertyAttribute>()
select property;
//Find all entity key properties
IEnumerable<PropertyInfo> idProperties =
from property in entityType.GetProperties()
from attribute in property.GetCustomAttributes(typeof(EdmScalarPropertyAttribute), true).Cast<EdmScalarPropertyAttribute>()
where attribute.EntityKeyProperty
select property;
We then can iterate over both these sets in the one foreach loop (by using .Concat) and for each property we will generate a statement that will set it to its default value (using a default(MyType) expression):
//Emit assignments that set the properties to their default value
foreach (PropertyInfo propertyInfo in relationSingleEndProperties.Concat(idProperties))
{
CodeExpression defaultExpression = new CodeDefaultValueExpression(new CodeTypeReference(propertyInfo.PropertyType));
CodePropertyReferenceExpression propertyReferenceExpression = new CodePropertyReferenceExpression(new CodeArgumentReferenceExpression("entity"), propertyInfo.Name);
clearEntityMethod.Statements.Add(new CodeAssignStatement(propertyReferenceExpression, defaultExpression));
}
This will generate statements like author.ID = default(int) and book.Author = default(Author) which are added to the generated method.
Now that we've generated code to wipe out the non-scalar properties on an entity, we need to compile this code. We do this by passing our CodeCompileUnit to a CSharpCodeProvider for compilation:
CSharpCodeProvider provider = new CSharpCodeProvider(); CompilerParameters parameters = new CompilerParameters(); parameters.GenerateInMemory = true; CompilerResults results = provider.CompileAssemblyFromDom(parameters, compileUnit);
We set GenerateInMemory to true, as we just want these types to be available as long as our App Domain exists. GenerateInMemory causes the types that we generated to be automatically loaded, so we now need to instantiate our new class and return it:
Type type = results.CompiledAssembly.GetType(namespaceName + "." + genTypeName); return (IEntityPropertyClearer)Activator.CreateInstance(type);
What DigitallyCreated Utilities does is keep a Dictionary of instances of these types in memory. If you call on it with an entity type that it hasn't seen before it will generate a new IEntityPropertyClearer for that type using the method we just created and save it in the dictionary. This means that we can reuse these instances as well as keep track of which entity types we've seen before so we don't try to regenerate the clearer class. The method that does this is the method that you call to get your entities wiped:
public static void ClearNonScalarProperties(EntityObject entity)
{
IEntityPropertyClearer propertyClearer;
//_PropertyClearers is a private static readonly IDictionary<Type, IEntityPropertyClearer>
lock (_PropertyClearers)
{
if (_PropertyClearers.ContainsKey(entity.GetType()) == false)
{
propertyClearer = GeneratePropertyClearer(entity);
_PropertyClearers.Add(entity.GetType(), propertyClearer);
}
else
propertyClearer = _PropertyClearers[entity.GetType()];
}
propertyClearer.Clear(entity);
}
Note that this is done inside a lock so that this method is thread-safe.
So now the question is: how much faster is doing this using code generation instead of just using reflection and dynamically calling Clear() etc?
I created a small benchmark that creates 10,000 Author objects (Authors have an ID, a Name and an EntityCollection of Books) and then wipes them with ClearNonScalarProperties (which uses the code generation). It does this 100 times. It then does the same thing but this time it uses reflection only. Here are the results:
| Average | Standard Deviation | |
|---|---|---|
| Using Code Generation | 466.0ms | 39.9ms |
| Using Reflection Only | 1817.5ms | 11.6ms |
As you can see, when using code generation, the code runs nearly four times as fast compared to when using reflection only. I assume that when an entity has more non-scalar properties than the paltry two that Author has this speed benefit would be even more pronounced.
Even though this code generation logic is harder to write than just doing dynamic method calls using reflection, the results are really worth it in terms of performance. The code for this is up as a part of DigitallyCreated Utilities (it's in trunk and not part of an official release at the time of writing), so if you're interested in seeing it in action go check it out there.
Entity Framework Compiled Queries Bake in the MergeOption
September 24, 2009 2:00 PM by Daniel Chambers
Updated on 2009/09/26
I've had some unexpected behaviour with change tracking and compiled queries while using .NET 3.5 SP1's Entity Framework. It's something that you likely won't notice and the resultant bug acts like a race condition: it only exhibits itself when things are executed in a particular order. Unfortunately, the Entity Framework documentation doesn't seem to make this behaviour clear in its documentation, which leaves you scratching your head when it actually occurs.
ObjectQuery.MergeOption allows you to control how the Entity Framework handles objects with respect to change tracking. I tend to set it to MergeOption.NoTracking when I want all objects created from a particular LINQ query returned pre-detached from the ObjectContext (very useful in web apps). However, when you want to query some objects, change their details and save the changes back to the DB, you will use MergeOption.AppendOnly, which is the default. This causes the ObjectContext to "remember" your objects and track the changes you make to them so it knows what it needs to save back to the DB when you go SaveChanges() on the ObjectContext.
Let me paint you a scenario. Maybe you use compiled queries to make your Entity Framework code quick as a fox. Maybe you use them to do something simple like get a Product from a database by its ID:
public static readonly Func<AdvWorksEntities, int, Product>
GetProduct = CompiledQuery.Compile(
(AdvWorksEntities context, int id) =>
(from product in context.Product
where product.ProductID == id
select product).FirstOrDefault());
Maybe you have two methods that call that compiled query (these are rather contrived examples):
public Product GetProductById(int id)
{
using (AdvWorksEntities context = new AdvWorksEntities())
{
context.Product.MergeOption = MergeOption.NoTracking;
return CompiledQueries.GetProduct(context, id);
}
}
public void ChangeProductName(int id, string newName)
{
using (AdvWorksEntities context = new AdvWorksEntities())
{
Product product = CompiledQueries.GetProduct(context, id);
product.Name = newName;
context.SaveChanges();
}
}
Nothing looks immediately wrong with that code (well, it didn't to me anyway).
Maybe you've got a user who opens the View Product page. The GetProductById method is called and the GetProduct compiled query is compiled and run. The user then decided the product has a crappy name, and he/she wants to change it. They change the name, and ChangeProductName gets called. The user then sees that the product name has, in fact, not been changed and gets pissed off.
What went wrong? You, the brow-beaten developer, open Visual Studio, start the app, and call ChangeProductName, which causes the GetProduct compiled query to be compiled and run. It works okay, the name is changed succesfully, and you're left scratching your head. You call it again, and it works again! What the hell is going on?
You restart the app and step through exactly what the user did. You call the GetProductById method, then call ChangeProductName. Bam, silent failure! SaveChanges returns successfully but your changes were not saved to the DB! The query is the same, but it's like somehow the MergeOption.NoTracking is coming over from the call to GetProductId. But this doesn't make sense since you're using a whole new ObjectContext! At this point you're cursing Entity Framework and looking at the documentation, which says nothing (to be fair, when you look into the details like I did, it makes sense. But it's just unintuitive and odd, and really needs to be highlighted in the documentation explicitly).
When this situation happened to me, I created a small test app to try and figure out why this was occurring. Here's what I found. The very first use of the GetProduct query causes it to get compiled. The query itself uses the ObjectQuery (which is IQueryable) that you set the MergeOption on. The expression tree for this query is saved and used for every query from then on. And here's the key: the saved expression tree includes the MergeOption that you set. So if you use MergeOption.NoTracking on the very first call to that compiled query, every query done with that compiled query from then on will be a NoTracking query, since the MergeOption is baked into it. It doesn't matter than you pass the compiled query a different ObjectContext with a different ObjectQuery that has a different MergeOption set. It will forevermore be NoTracking.
So what can you do? At this point, it seems that you will need different compiled queries for the different MergeOptions. If you use GetProduct with NoTracking and with AppendOnly, you will now need GetProductWithNoTracking and GetProductWithAppendOnly.
So watch out for this issue; it's really easy to run into because the query's MergeOption is set outside of the compiled query's declaration, therefore it's not obvious that it is actually baked into the compiled query. And it's a pain to discover, because it doesn't crop up unless you execute your methods in a particular order.
Update: I've developed a solution that makes this problem easier to deal with: a class that transparently duplicates a compiled query, allowing you to easily have multiple versions of a compiled query, one per MergeOption. The solution is currently in the DigitallyCreated Utilities repository and the tutorial for it can be found here.
DigitallyCreated Utilities Now Open Source
August 05, 2009 2:00 PM by Daniel Chambers
My part time job for 2009 (while I study at university) has been working at a small company called Onset doing .NET development work. Among other things, I am (with a friend who also works there) re-writing their website in ASP.NET MVC. As I wrote code for their website I kept copy/pasting in code from previous projects and thinking about ways I could make development in ASP.NET MVC and Entity Framework even better.
I decided there needed to be a better way of keeping all this utility code that I kept importing from my personal projects into Onset's code base in one place. I also wanted a place that I could add further utilities as I wrote them and use them across all my projects, personal or commercial. So I took my utility code from my personal projects, implemented those cool ideas I had (on my time, not on Onset's!) and created the DigitallyCreated Utilities open source project on CodePlex. I've put the code out there under the Ms-PL licence, which basically lets you do anything with it.
The project is pretty small at the moment and only contains a handful of classes. However, it does contain some really cool functionality! The main feature at the moment is making it really really easy to do paging and sorting of data in ASP.NET MVC and Entity Framework. MVC doesn't come with any fancy controls, so you need to implement all the UI code for paging and sorting functionality yourself. I foresaw this becoming repetitive in my work on the Onset website, so I wrote a bunch of stuff that makes it ridiculously easy to do.
This is the part when I'd normally jump into some awesome code examples, but I already spent a chunk of time writing up a tutorial on the CodePlex wiki (which is really good by the way, and open source!), so go over there and check it out.
I'll be continuing to add to the project over time, so I thought I might need some "project values" to illustrate the quality level that I want the project to be at:
- To provide useful utilities and extensions to basic .NET functionality that saves developers' time
- To provide fully XML-documented source code (nothing is more annoying than undocumented code)
- To back up the source code documentation with useful tutorial articles that help developers use this project
That's not just guff: all the source code is fully documented and that tutorial I wrote is already up there. I hate open source projects that are badly documented; they have so much potential, but learning how they work and how to use them is always a pain in the arse. So I'm striving to not be like that.
The first release (v0.1.0) is already up there. I even learned how to use Sandcastle and Sandcastle Help File Builder to create a CHM copy of the API documentation for the release. So you can now view the XML documentation in its full MSDN-style glory when you download the release. The assemblies are accompanied by their XMLdoc files, so you get the documentation in Visual Studio as well.
Setting all this up took a bit of time, but I'm really happy with the result. I'm looking forward to adding more stuff to the project over time, although I might not have a lot of time to do so in the near future since uni is starting up again shortly. Hopefully you find what it has got as useful as I have.
Dynamic Queries in Entity Framework using Expression Trees
June 06, 2009 2:00 PM by Daniel Chambers (last modified on January 13, 2011 12:24 PM)
Most of the queries you do in your application are probably static queries. The parameters you set on the query probably change, but the actual query itself doesn't. That's why compiled queries are so cool, because you can pre-compile and reuse a query over and over again and just vary the parameters (see my last blog for more information).
But sometimes you might need to construct a query at runtime. By this I mean not just changing the parameter values, but actually changing the query structure. A good example of this would be a filter, where, depending on what the user wants, you dynamically create a query that culls a set down to what the user is looking for. If you've only got a couple of filter options, you can probably get away with writing multiple compiled queries to cover the permutations, but it only takes a few filter options before you've got a lot of permutations and it becomes unmanageable.
A good example of this is file searching. You can filter a list of files by name, type, size, date modified, etc. The user may only want to filter by one of these filters, for example with "Awesome" as the filename. But the user may also want to filter by multiple filters, for example, "Awesome" as the filename, but modified after 2009/07/07 and more than 20MB in size. To create a static query for each permutation would result in 16 queries (4 squared)!
My first foray into creating dynamic queries is a bit less ambitious than the above example, however. I have a scenario where I need to pull out a number of Tag objects from the database by their IDs. However, the number of the Tag objects needed is determined by the user. They may select 3 Tags, or they may select 6 Tags, or they may select 4 tags; it's up to them.
The most boring approach is, of course, to get each Tag out of the database individually with its own query (the "get each Tag individually" approach):
IList<Tag> list = new List<Tag>();
foreach (int tagId in WantedTagIds)
{
int localTagId = tagId;
Tag theTag = (from tag in context.Tag
where
tag.Account.ID == AccountId &&
tag.ID == localTagId
select tag).First();
list.Add(theTag);
}
You could compile that query to make it run faster, but it's still a slow operation. If the user wants to get 6 Tags, you need to query the database 6 times. Not very cool.
This is where dynamic queries can step in. If the user asks for 3 Tags, you can generate a where clause that gets all three Tags in one go; essentially: tag.ID == 10 || tag.ID == 12 || tag.ID == 14. That way you get all three Tags in one query to the database. So, I wrote some generic type-safe code to perform exactly that: generating a where clause expression from a list of IDs so that a Tag with any of those IDs is retrieved.
To understand how I did this, you need to understand how the where clause in an LINQ expression works. It is easiest to understand if you look at the method-chain form of LINQ rather than the special C# syntax. It looks like this:
IQueryable<Tag> tags = context.Tag.AsQueryable()
.Where(tag => tag.ID == 10);
The Where method takes a parameter that looks like this: Expression<Func<Tag, bool>>. Notice how the Func delegate is wrapped in an Expression? This means that instead of creating an actual anonymous method for the Func delegate, the compiler will instead convert your lambda expression into an Expression Tree.
An Expression Tree is a representation of your expression in an object tree. Here is an object tree that shows the main objects in the expression tree generated by the compiler for the lambda expression in the above example's Where method:
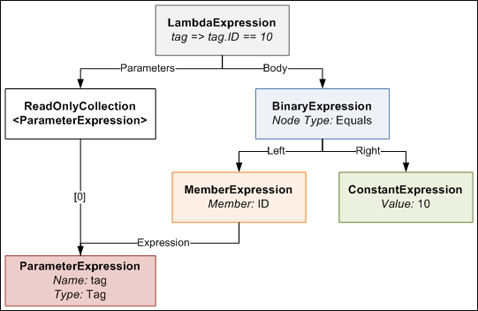
The LambdaExpression has a collection of ParameterExpressions, which are the parameters on the left side of the => symbol in the code. The actual Body of the lambda is made up of a BinaryExpression of type Equals, whose Right side is a ConstantExpression that contains the value of 10, and whose Left side is a MemberExpression. A MemberExpression represents the access of the ID property on the tag parameter.
So if we wanted to represent a more complex expression such as:
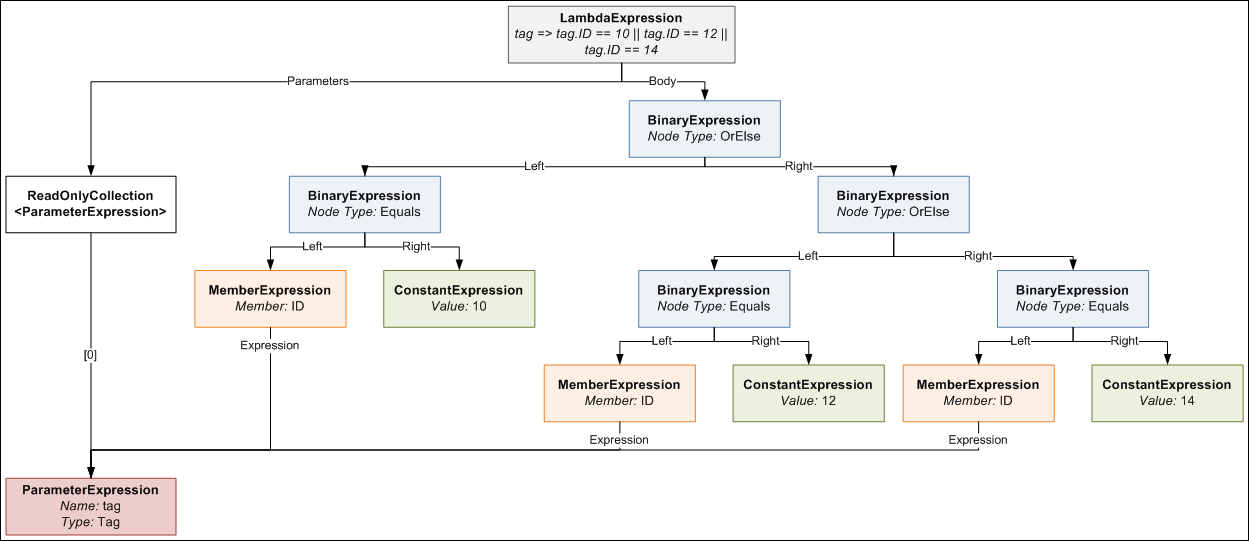
tag => tag.ID == 10 || tag.ID == 12 || tag.ID == 14
this is what the expression tree would look like. It looks a bit daunting, but computers are very good at trees, so writing code to generate such a tree is not too difficult with the help of a little recursion.
{kind=link}
I defined a special utility method that allows you to create an expression tree like the one above that results in a Where expression that accepts a particular tag so long as its ID is in a certain set of IDs. The method is generic and reusable across anywhere where you need a Where filter that gets "this value, or this value, or this value... etc". The public method looks like this:
public static Expression<Func<TValue, bool>> BuildOrExpressionTree<TValue, TCompareAgainst>(
IEnumerable<TCompareAgainst> wantedItems,
Expression<Func<TValue, TCompareAgainst>> convertBetweenTypes)
{
ParameterExpression inputParam = convertBetweenTypes.Parameters[0];
Expression binaryExpressionTree = BuildBinaryOrTree(wantedItems.GetEnumerator(), convertBetweenTypes.Body, null);
return Expression.Lambda<Func<TValue, bool>>(binaryExpressionTree, new[] { inputParam });
}
It's stuffed full of generics which makes it look more complicated than it really is. Here's how you call it:
List<int> ids = new List<int> { 10, 12, 14 };
Expression<Func<Tag, bool>> whereClause = BuildOrExpressionTree<Tag, int>(wantedTagIds, tag => tag.ID);
As I explain how it works, I suggest you keep an eye on the last expression tree diagram. The method defines two generic types, one called TValue which represents the value you are comparing, in this case the Tag class. The other generic type is called TCompareAgainst and is the type of the value you are comparing against, in this case int (because the Tag.ID property is an int).
You pass the method an IEnumerable<TCompareAgainst>, which in our case is an IEnumerable<int>, because we have a list of IDs we are comparing against.
The second parameter ("convertBetweenTypes") can be a bit confusing; let me explain. The expression we are defining for the Where clause takes a Tag and returns a bool (hence the Func<Tag, bool> typed expression). Since the set of values we are comparing against are ints, we can't just do an == between the Tag and an int. To be able to do this comparison, we need to somehow "convert" the Tag we receive into an int for comparison. This is where the second parameter comes in. It defines an Expression that takes a Tag and returns an int (or in generic terms takes a TValue and returns a TCompareAgainst). When you write tag => tag.ID, the compiler generates an Expression Tree that contains a MemberExpression that accesses ID on the tag ParameterExpression. This means wherever we need to do a Tag == int, we instead do a Tag.ID == int by substituting the Tag.ID MemberExpression generated in the place of the Tag. Here's a diagram that explains what I'm ranting about.
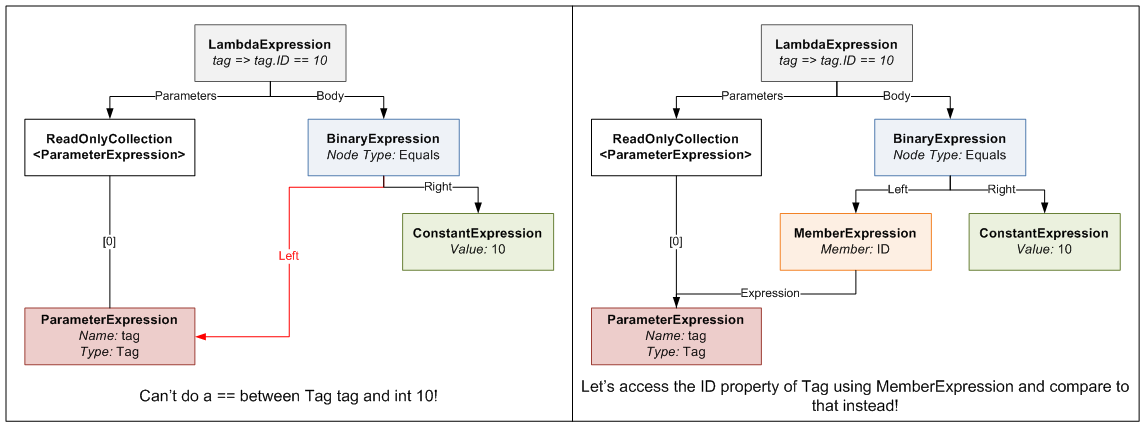{kind=link}
The main purpose of this method is to create the final LambdaExpression that the method returns. It does this by attaching the expression tree built by the BuildBinaryOrTree method (we'll get into this in a second) and the ParameterExpression from the convertBetweenTypes to the final LambdaExpression object.
The BuildBinaryOrTree method looks like this:
private static Expression BuildBinaryOrTree<T>(
IEnumerator<T> itemEnumerator,
Expression expressionToCompareTo,
Expression expression)
{
if (itemEnumerator.MoveNext() == false)
return expression;
ConstantExpression constant = Expression.Constant(itemEnumerator.Current, typeof(T));
BinaryExpression comparison = Expression.Equal(expressionToCompareTo, constant);
BinaryExpression newExpression;
if (expression == null)
newExpression = comparison;
else
newExpression = Expression.OrElse(expression, comparison);
return BuildBinaryOrTree(itemEnumerator, expressionToCompareTo, newExpression);
}
It takes an IEnumerator that enumerates over the wantedItems list (from the BuildOrExpressionTree method), an expression to compare each of these wanted items to (which is the compiler-generated MemberExpression from BuildOrExpressionTreeMethod), and an expression from a previous recursion (starts off as null).
The method creates an Equals BinaryExpression that compares the expressionToCompareTo and the current itemEnumerator value. It then joins this in an OrElse BinaryExpression comparison with the expression from previous recursions. It then takes this new expression and passes it down to the next recursive call. This process continues until itemEnumerator is exhausted at which point the final expression tree is returned.
Once this returned expression tree is placed in its LambdaExpression by the BuildOrExpressionTree method, you end up with a pretty expression tree like this one shown previously. We can then use this expression tree in the where clause of a LINQ method chain query.
Here's the final "generated where clause" query in action:
using (DHEntities context = new DHEntities())
{
int[] wantedTagIds = new[] {12, 24, 1, 4, 32, 19};
Expression<Func<Tag, bool>> whereClause = ExpressionTreeUtil.BuildOrExpressionTree<Tag, int>(wantedTagIds, tag => tag.ID);
IQueryable<Tag> tags = context.Tag.Where(whereClause);
IList<Tag> list = tags.ToList();
}
So how much better is this approach, which is decidedly more complex than the simple "get each Tag at a time" approach? Is it worth the effort? I performed some benchmarks similar to the ones I did in the last blog to find out.
In one benchmark run, I ran these queries, each a hundred times, each getting out the same 6 tags:
- The "get each Tag individually" query (uncompiled)
- The "get each Tag individually" query (compiled)
- The "generated where clause" query. The where clause was regenerated each time.
I then ran the benchmark 100 times so that I could get more reliable averaged values. These are the results I got:
| Average | Standard Deviation | |
|---|---|---|
| "Get Each Tag Individually" Query Loop (Uncompiled) | 3212.2ms | 40.2ms |
| "Get Each Tag Individually" Query Loop (Compiled) | 1349.3ms | 24.2ms |
| "Generated Where Clause" Query Loop | 197.8ms | 5.3ms |
As you can see, the Generated Where Clause approach is quite a lot faster than the individual queries. We can see compiling the Individual query helps, but not enough to beat the Generated Where Clause query, which is faster even though it is recompiled each time! (You can't precompile a dynamic query, obviously). The Generated Where Clause query is 6.8 times faster than the compiled Individual query and a whopping 16.2 times faster than the uncompiled Individual query.
Even though dynamic queries are lots harder than normal static queries, because you have to manually mess with Expression Trees, there are large payoffs to be had in doing so. When used in the appropriate place, dynamic queries are faster than static queries. They could also potentially make your code cleaner, especially in the case of the filter example I talked about at the beginning of this blog. So consider getting up to speed with Expression Trees. It's worth the effort.
Making Entity Framework as Quick as a Fox
June 04, 2009 2:00 PM by Daniel Chambers
Entity Framework is the new (as of .NET 3.5 SP1) ORM technology for the .NET Framework. ORM technologies are widely accepted as the "better" way of accessing relational databases, because they allow you to work with relational data as objects in the world of objects. However, ORM tech can be slower than writing manual SQL queries yourself. This can be seen in this blog that benchmarks Entity Framework versus LINQ to SQL and a manual SQLDataReader.
Hardware is cheap (compared to programmer labour, which is not) so getting a faster machine could be an effective strategy to counter performance issues with ORM. However, what if we could squeeze some extra performance out of Entity Framework with only a little effort?
This is where Compiled Queries come in. Compiled queries are good to use where you have one particular query that you use over and over again in the same application. A normal query (using LINQ) is passed to Entity Framework as an expression tree. Entity Framework translates it into a command tree that is then translated by a database-specific provider into a query against a database. It does this every time you execute the query. Obviously, if this query is in a loop (or is called often) this is suboptimal because the query is recompiled every time, even though all that's probably changed is the parameters in the query. Compiled queries ensure that the query is only compiled once, and the only thing that varies is the parameters.
I created a quick benchmark app to find out just how much faster compiled queries are against normal queries. I'll illustrate how the benchmark works and then present the results.
Basically, I had a particular non-compiled LINQ to Entities query which I ran 100 times in a loop and timed how long it took. I then created the same query, but as a compiled query instead. I ran it once, because the query is compiled the first time you run it, not when you construct it. I then ran it 100 times in a loop and timed how long it took. Also, before doing any of the above, I ran the non-compiled query once, because it seemed to take a long time for the very first operation using the Entity Framework to run, so I wanted that time excluded from my results.
The non-compiled query I ran looked like this:
IQueryable<Transaction> transactions =
from transaction in context.Transaction
where
transaction.TransactionDate >= FromDate &&
transaction.TransactionDate <= ToDate
select transaction;
List<Transaction> list = transactions.ToList();
As you can see, it's nothing fancy, just a simple query with a small where clause. This query returns 39 Transaction objects from my database (SQL Server 2005).
The compiled query was created like this:
Func<DHEntities, DateTime, DateTime, IQueryable<Transaction>>
query;
query = CompiledQuery.Compile(
(DHEntities ctx, DateTime fromD, DateTime toD) =>
from transaction in ctx.Transaction
where
transaction.TransactionDate >= fromD &&
transaction.TransactionDate <= toD
select transaction);
As you can see, to create a compiled query you pass your LINQ query to CompiledQuery.Compile() via a lambda expression that defines the things that the query needs (ie the Object Context (in this case, DHEntities) and the parameters used (in this case two DateTimes). The Compile function will return a Func delegate that has the types you defined in your lambda, plus one extra: the return type of the query (in this case IQueryable<Transaction>).
The compiled query was executed like this:
IQueryable<Transaction> transactions = query.Invoke(context, FromDate, ToDate); List<Transaction> list = transactions.ToList();
I ran the benchmark 100 times, collected all the data and then averaged the results:
| Average | Standard Deviation | |
|---|---|---|
| Non-compiled Query Loop | 534.1ms | 20.6ms |
| Compiled Query Loop | 63.1ms | 0.6ms |
The results are impressive. In this case, compiled queries are 8.5 times faster than normal queries! I've showed the standard deviation so that you can see that the results didn't fluctuate much between each benchmark run.
The use case I have for using compiled queries is doing database access in a WCF service. I expose a service that will likely be beaten to death by constant queries from an ASP.NET MVC webserver. Sure, I could get larger hardware to make the WCF service go faster, or I could simply get a rather massive performance boost just by using compiled queries.