
Variable Capture in C# with Anonymous Delegates
April 06, 2009 2:00 PM by Daniel Chambers
Anonymous delegates (or, if you're using C# 3.0, lambda expressions) seem fairly simple at first sight. It's just a class-less method that you can pass around and call at will. However, there are some intricacies that aren’t apparent unless you look deeper. In particular, what happens if you use a variable from outside the anonymous delegate inside the delegate? What happens when that variable goes out of scope (say it’s a local variable and the method that contained it returned)?
I’ll run through some small examples that will explain something called “variable capture” and how it relates to anonymous delegates (and therefore, lambda expressions).
The code below for loops and adds a new lambda that returns the index variable from the for loop. After the loop has concluded, all the lambdas created are run and their results written to the console. FYI, Func<TResult> is a .NET built-in delegate that takes no parameters and returns TResult.
List<Func<int>> funcs = new List<Func<int>>();
for (int j = 0; j < 10; j++)
funcs.Add(() => j);
foreach (Func<int> func in funcs)
Console.WriteLine(func());
What will be outputted on the console when this code is run? The answer is ten 10s. Why is this? Because of variable capture. Each lambda has “captured” the variable j, and in essence, extended its scope to outside the for loop. Normally j would be thrown away at the end of the for loop. But because it has been captured, the delegates hold a reference to it. So its final value, after the loop has completed, is 10 and that’s why 10 has been outputted 10 times. (Also, j won’t be garbage collected until the lambda is, since it holds a reference to j.)
In this next example, I’ve added one line of seemingly redundant code, which assigns the j index variable to a temporary variable inside the loop body. The lambda then uses tempJ instead of j. This makes a massive difference to the final output!
List<Func<int>> funcs = new List<Func<int>>();
for (int j = 0; j < 10; j++)
{
int tempJ = j;
funcs.Add(() => tempJ);
}
foreach (Func<int> func in funcs)
Console.WriteLine(func());
This piece of code outputs 0-9 on the console. So why is this so different to the last example? Whereas j’s scope is over the whole for loop (it is the same variable across all loop iterations), tempJ is a new tempJ for every time the loop is run. This means that when the lambdas capture tempJ, they each capture a different tempJ that contains what j was for that particular iteration of the loop.
In this final example, the lambda is created and evaluated within the for loop (and no longer uses tempJ).
for (int j = 0; j < 10; j++)
{
Func<int> func1 = () => j;
Console.WriteLine(func1());
}
This code is similar to the first example; the lambdas capture j whose scope is over the whole for loop. However, unlike the first example, this outputs 0-9 on the console. Why? Because the lambda is executed inside each iteration. So at the point at which each lambda is executed j is 0-9, unlike the first example where the lambdas weren’t executed until j was 10.
In conclusion, using these small examples I’ve shown the implications of variable capture. Variable capture happens when an anonymous delegate uses a variable from the scope outside of itself. This causes the delegate to “capture” the variable (ie hold a reference to it) and therefore the variable will not be garbage collected until the capturer delegate itself is garbage collected.
Value Type Boxing in C#
March 12, 2009 2:00 PM by Daniel Chambers
There are times when I am surprised because I come across some basic principle or feature in a programming language that I just didn't know about but really should have (see the "Generics and Type-Safety" blog for an example). The most recent example of this was in my Enterprise .NET lecture where they asked us to define what boxing and unboxing was. I'd heard of it in relation to Java, because Java has non-object value types that need to be converted to objects sometimes (the process of "boxing") so they can be used with Java's crappy generics system. But since, in C#, even an int is an object with methods, I assumed that boxing and unboxing was not done in C#.
I was wrong. C# indeed does boxing and unboxing! At first, this didn't make sense. My incomplete understanding of boxing (in relation to Java) was that value types were stored only on the stack (yes, this is a little inaccurate) and when you needed to put them on the heap, you had to box them. In C#, I thought everything was an object, so this process would have been redundant.
Wrong. .NET (and therefore C#) has value types, which are boxed and unboxed transparently by the CLR. Value types in C# derive from the ValueType class which itself derives from Object. Structs in C# are automatically derived from ValueType for you (therefore you cannot do inheritance with structs). Unlike in Java, value types are still objects: they can have methods, fields, properties, events, etc.
Why are value types good? When .NET deals with a value type, it stores the object's data inline in memory. This means when the variable is on the stack, the data is stored directly in stack-space. When the variable is inside a heap object, the data is stored directly inside the heap object. This is different to reference types, where instead of the data being stored inline, a pointer to the data which is somewhere on the heap is stored inline. This means it takes longer to access a reference type than a value type as you have to read the pointer, then read the location the pointer points to.
Boxing kills this performance increase you get when you use value types. When you box (or more accurately, the CLR boxes) a value type, it essentially wraps it in a reference type object that is stored on the heap and then uses a reference to point to it. Your value type is now a reference type. So not only do you need to look up a reference to get to the final data, you have to spend time creating the wrapper object at runtime.
When does boxing happen? The main place to watch out for is when you pass a value type around as Object. A common place this might happen is if you use ArrayList. If you do, it's time to move on. :) .NET 2.0 introduced generics and you should use them. Generics play nice with value types, so try using a List<T> instead.
So what do I mean when I say "generics play nice with value types"? Unlike Java, whose generics system sucks (it does type erasure, which is half-arsed generics), .NET understands generics at runtime. This means when you define, for example, a List<int>, .NET realises that int is a value type and then will allocate ints inline inside the List as per the "inline storage" explanation above. This is lots better than Java or ArrayList's behaviour, where each element in the array is a pointer to a location on the heap and because the value type that had been added has been boxed.
In hindsight, especially when I think about it all from a C++ perspective, I should have known C# did value type boxing. How could it have value types and not? But I guess I just didn't join the dots.
Sleep Display
November 01, 2008 2:00 PM by Daniel Chambers
I've always had a problem when I've left my computer on at night. My screens, the two 24" beasts that they are, light up my room like its 12 o'clock midday. It makes it rather difficult to get to sleep. My solution, in the past, was to temporarily change my Windows power configuration so that my monitor would sleep itself after one minute of inactivity. A clunky and annoying solution, to be sure.
This weekend, I'd had enough. I searched around on the net for a program that would allow me to sleep my displays immediately, without the need for dicking around in power configuration settings.
Sure enough, this bloke has a program that'll do just that. However, he expects to be paid twenty whole dollars for it. I choked when I saw that; turning off your screens cannot be so hard as to require a 20 dollar (US dollars as well!) payment for it. So I did some more searching. Sure enough, its quite literally one method call to send your displays to sleep.
So I whipped up a program to do it: Sleep Display. I won't repeat here what I've already written on its webpage, so pop on over there to read up on it.
For those interested, here is how you sleep your monitors in C# (note this is not actually a class from Sleep Display, I've cut out loads of code to just get it down to the bare essentials):
using System;
using System.Runtime.InteropServices;
using System.Threading;
using System.Windows.Forms;
namespace DigitallyCreated.SleepDisplay
{
public class Sleeper
{
//From WinUser.h
private const int WM_SYSCOMMAND = 0x0112;
private const int SC_MONITORPOWER = 0xF170;
//Not from WinUser.h (from MSDN doco about
//SC_MONITORPOWER)
private const int SC_MONITORPOWER_SHUTOFF = 2;
public void SleepDisplay()
{
Form form = new Form();
DefWindowProcA((int)form.Handle, WM_SYSCOMMAND,
SC_MONITORPOWER, SC_MONITORPOWER_SHUTOFF);
}
[DllImport("user32", EntryPoint = "DefWindowProc")]
public static extern int DefWindowProcA(int hwnd,
int wMsg, int wParam, int lParam);
}
}
Basically, all you're doing is sending a Windows message to the default window message handler by calling a Win32 API. The message simply tells Windows to sleep the monitor. Note the use of DllImport and public static extern. This is basically where you map a call to a native (probably C or C++) function into C#. C# will handle the loading of the DLL and the marshalling and the actual calling of the function for you. It's pretty nice.
The Form is needed because DefWindowProc requires a handle to a window and the easiest way I knew how to get one of those was to simply create a Form and get its Handle. DefWindowProc has its doco on MSDN here and the doco for the types of WM_SYSCOMMAND message you can send is here.
As you can see, the process is not rocket-science, nor is it worth 20 whole bucks. In fact, the installer I created was more of a pain than the app itself. I decided to try and use Windows Installer instead of NSIS. I used Windows Installer XML (WiX) which seems to be an open-source project from Microsoft that allows you to create Windows Installer packages and UIs by writing XML. It's also got a plugin for Visual Studio.
WiX is... alright. It's a real bitch to work with, simply because I'm nowhere near a Windows Installer pro so I don't really understand what's going on. Windows Installer is massive and I only scratched the surface of it when doing the installer for Sleep Display. The problem with WiX, really, is that it has a massive learning curve. If you're interested in learning more about WiX, I suggest you grab v3.0 (Beta) and install it, then go check out the (huge) tutorial they've got here. Then prepare to go to bed at 6.30AM after hours of pain like I did. :)
Broken Process Explorer: Missing .NET Performance Counters
September 28, 2008 3:00 PM by Daniel Chambers
For a while, I've had the problem where my .NET performance counters have been missing from my system. This had the side effect of breaking Process Explorer's ability to highlight which processes are .NET processes. Process Explorer checks for the presence of the performance counters to see whether .NET is installed, and if it doesn't find them it disables its .NET process detection.
Apparently a lot of people encounter this problem, since point 31 and 32 on the Process Explorer FAQ try to address it. However, the solutions they provide have never worked for me. However, recently I figured out what was stuffing it up. If you're in the same position as me and the FAQ doesn't help you, you might want to check this out. I run Vista x64, so if you're running XP still I can't guarantee this will work for you, since I haven't looked at it on XP.
Browse to HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\.NETFramework\Performance in regedit. Have a look at the "Library" value. Does it say "donotload_mscoree.dll"? If so, that's your problem. Change it to mscoree.dll and you're set. Apparently, MSDN says this about why it's not loaded:
If the .NET Framework is installed on a system that is running Windows XP, any process that uses the Performance Data Helper (PDH) functions to retrieve performance counters may stop responding ("hang") for 60 seconds when the process exits.
...
This delay is caused by a bug in the .NET Framework performance extension DLL, Mscoree.dll.
Hence, they recommend disabling the counters by renaming the library to donotload_mscoree.dll. That's an awesome solution, Microsoft! Why not just fix your bugs?! Luckily, they say it only applies to .NET 1.0 and 1.1, which are so old and irrelevent I wouldn't touch them with a barge pole (no generics, for christ's sake!). However, they haven't looked at this article since November 15, 2003, so maybe it still applies to .NET 2.0+. Who knows. You'd hope they'd have fixed this epic fail bug by now.
I reckon that Visual Studio or SQL Server must have made that change in the registry, because I don't have this problem on my computer at work (Java programming, so no VS). I've also always had this problem on my home machines and I've also always has VS installed on them. Hopefully, Microsoft didn't disable it for a good reason, because I've undone it now... but somehow I doubt they'd deliberately be breaking performance counters. After all, the people who actually use them are probably .NET developers and they almost definately use Visual Studio.
Crysis Warhead: Worth Paying For, But Far Better Pirated
September 28, 2008 2:00 PM by Daniel Chambers
Personally, I hate Digital Rights Management (DRM). Hate it with a vengeance. In music, in games, it doesn't matter. Contrary to what the execs in their ivory towers believe, DRM serves one purpose and one purpose only: to piss off and prevent legitimate customers from playing and using their purchased goods.
Case in point: Crysis Warhead. I was actually extremely surprised, in a pleasant way, when EA (yes, EA!) released Crysis Warhead (and the original Crysis) on Steam for purchase. More impressively, they decided not to charge the Rest Of The World (ie. not the USA) far extra for exactly the same thing), otherwise known as price gouging. It costs, very reasonably, US$30. (Unfortunately, they are still gouging us for Crysis 1. US$40 if you download from the USA, US$60 if you download from Australia. What a crock.)
Obviously, releasing Crysis & Crysis Warhead on Steam is a toe-in-the-water test by EA to see the response from consumers. Certainly, Crytek, the developers of Crysis have been whinging like stuck pigs about the rampant pirating of Crysis. Of course, the extreme levels of piracy have nothing to do with the fact that Crysis runs like crap on the computers that your customers spent a lot of money upgrading to play your game, unless you're willing to crank down the graphics (which defeats the purpose of upgrading). It's alright, just blame your customers because they're obviously not smart enough to see a brilliant product when they see it. Oops, I've started foaming at the mouth... anyway, back to Crysis Warhead on Steam.
I'm always harping on about how, if games companies were to offer a decent product I want, not price-gouge me because I live in the Rest Of The World, not load it with crippling DRM, and optionally, offer the game as a download through Steam, I would be more than happy to throw my money at them like there was no tomorrow. So I decided now, with EA (yes, EA!!) putting Crysis Warhead on Steam as a test, was the time to put my money where my mouth is.
So I purchased Crysis Warhead.
That was a mistake, of sorts.
Don't get me wrong. The game is great. I like the game. I enjoyed Crysis, once I got past the terrible graphics performance and the crippling kick in the 'nads that I received upon realising those hundreds of dollars spent upgrading my PC were worthless since it still played like crap. Crysis Warhead is more of that (including the kick to the 'nads, but also the great gameplay). The problem is the DRM it comes infected with.
Stupid me. Thinking that some god somewhere had finally showed his hand and guided EA back to the path of righteousness (or some shit). I expected, having being released on Steam, EA would be utilizing Steam's DRM mechanism to protect their game. I was so wrong.
Steam's DRM is the only DRM that I have ever used that doesn't kick the purchaser in a very painful place. It never gets in the way. It has never, ever, prevented me from playing a game I own. I can play my games on whatever damn PC I want. I can redownload my games for free if I lose them in a hard-drive failure or something. I never get told that I can't play my game because I have some advanced computer-user tool installed. These days, it doesn't collapse in a smoking heap on launch day, preventing customers from playing the game. The only thing it asks is that I log in to Steam, which I don't mind. Why don't I mind? Because lots of games use Steam. If every different game used a different "log in please" program, I'd get annoyed. But with Steam, I can log in and get all my games, because it has them all (unless you live in The Rest Of The World, in which case it doesn't. I feel more mouth-foam on the way... must stay focused!).
Turns out, Crysis Warhead comes with the same DRM malware that has pissed off so many people who tried to own Spore: SecuROM. Incidentally, SecuROM is made by Sony, a company I loathe because of the contempt it holds for its customers. Crysis Warhead also came loaded with a load of bloatware as well.
When I started the game, Steam oddly requested admin rights (through UAC), which it never does. I granted it, and it began installing stuff, except it didn't have a UI, programs just popped up wanting to install. I was slightly suspicious, so I opened Process Explorer so I could see what the hell was going on. Steam was running some install script for Crysis Warhead, which was spawning off installers for various programs including Punkbuster. I let them through, but when it tried to foist off GameSpy Comrade on me by just throwing the installer in my face, I said stuff this and cancelled the GameSpy installer.
I ran the game again and was presented with... "A required security module cannot be activated. This program cannot be executed (5024)." I pressed OK, and was returned to Steam sans Crysis Warhead. Shit, I thought, maybe cancelling that GameSpy Comrade cancer stuffed up some DRM-installing process, because it's damn obvious now that this isn't using Steam's DRM.
So after around 15-20 minutes of poking around on the Steam forums, I discovered why I was not allowed to play the game I legally purchased with my hard-earned money: I was running Process Explorer. For those who haven't heard of Process Explorer, its basically a fancy Task Manager that provides me with more information about what my computer's doing. It is not a cracking tool. It does not reverse engineer programs. It's even made by Microsoft, not some dodgy back-room company. But apparently, the joint Sony and EA gods of contempt decree that I'm not allowed to use it.
So in summary: I paid money for a game and was unable to play it after purchase. I then had to decode a uselessly obscure error message to work around the DRM before I could play. On the other side of the fence, I could have done the wrong thing and asked my friend Mr B Torrent to get me Crysis Warhead and I would have been playing immediately, since the Sony DRM would have been cracked out for me. Do tell me, which process do you think actually allows the player to actually play the game? Really, has the Sony DRM prevented the Mr B Torrent edition as is its purpose? No. The only, the only, thing it has done is to waste the time of legitimately paying customers like myself. Correct me if I'm wrong, but since I'm paying for the game, I ought to be getting a better, not worse, experience than those who steal it.
Daniel James, CEO of the games company Three Rings, in his post on Penny Arcade laid the smackdown on DRM and said it exactly as I feel about it:
DRM takes a big poo on your best customers -- the ones who've given you money -- whilst doing nothing practical to prevent others from 'stealing' your precious content juices. Worse, it makes these renegades feel nice and righteous about sticking it to 'the man'. Stop trying to persuade people to love you more by hitting them a rusty pipe. Put down the pipe, and give up on DRM.
He also says this, in reference also to the music industry (emphasis mine):
'Not fair', the vendor of music or packaged software cries. Well, tough shit. Nobody added your business to the list of protected species, despite what your lobbyists and lawyers say. Find a business model that's actually appropriate to the 21st century, and perhaps scale back your expectations of vast profits accordingly (oh, and fire some lawyers and lobbyists, too, please). For example, as some musicians have done by returning to live performance as their main source of revenue.
I yelled in joy when I read that. Finally, someone who gets it. In terms of the movie and music industries, trying to force your customers to use your far outdated business model by corrupting politicians and bashing people with the "law" (and it's not the law: they are just forcing you to do what they want because you can't afford a lawyer to defend yourself) is absolutely and undeniably despicable. And they wonder why people now take pleasure in stealing music etc.
And don't tell me that "oh the retail game industry can't make money if we make these changes you want, waah!". That is crap. Look at Valve. They make games that are quality and people want them. They sell them at a reasonable price that is the same no matter where you live in the world. Their DRM is Steam's DRM, so it's not obnoxious. People can purchase their games online and download them directly to their PCs. They can play the games on whatever PC they like, whenever they like. Their games play on the majority of PCs out there (Valve uses Steam to do hardware surveys to discover what level of computer they should target their games at. That data is available to all game developers for free). And because of all this, they make tonnes of money.
So don't tell me its not possible to make money without DRM. The writing is on the wall. DRM doesn't work. It never will. Treat your customers with respect and you'll receive the same back.
Please note that I do not condone piracy as a solution to the problem. Developers deserve your money, but they have to earn it. If you don't think a game is worth your money, don't pay for it and don't play it. Pay for and play games that are brilliant and don't treat you like a criminal. Speak with your wallet; money is the language that corporations talk in. Piracy only proves to them that you would take their product if there was no piracy (hence DRM). Show them that you wouldn't take their crappy product at all. They'll learn very quickly when they don't have piracy figures to fall back on as an excuse as to why people aren't buying their games.
PowerShell Tries to be Smart, Shoots Self in Foot
September 27, 2008 2:00 PM by Daniel Chambers
I used to like PowerShell a lot. It seemed like a decent scripting language that extended the .NET Framework, so anything I could do in .NET I could do in PowerShell. That's still true, except I find that every time I try to use PowerShell to quickly whip up some small solution, I spend far too long messing around getting choked by its black magic. It would have been faster to write a command-line app in full blown C#.
I guess you could say that if I knew PowerShell better, this wouldn't happen, and that would be true. However, I don't write full blown applications in PowerShell... that's not what it's for. I'm not a sys-admin and don't want to be, so I don't spend a lot of time scripting. So the few times I want to write a quick script I just want to quickly crack out a script and have done with it.
My current rage against PowerShell has been evoked by the way it handles filepaths. PowerShell lets you put wildcards, such as [0-7] or *, into your paths that you pass to its cmdlets to do things. The problem occurs when the directories you are using contain characters that are used for wildcards (the square brackets, particularly). PowerShell totally craps out. I'll run you through a short example.
Create a directory called "Files [2000-2008]" in C:, then under that create two other directories "Word Docs" and "Excel Docs from my Sister [2007]". Open up PowerShell and cd to C:\Files [2000-2008]. Now type "cd" and try to use tab completion to go into Word Docs or Excel Docs. Oh what? It's not working? Yep, broken. Okay, so you'll have to type out "cd 'Word Docs'" to move into that directory. Dodgy, but no real problem.
Okay, now "cd .." back into Files. Now try to get into Excel Docs. Maybe you'll type (since tab completion is rooted) "cd 'Excel Docs from my Sister [2007]'". Nup, doesn't work, apparently it doesn't exist! What crack is PowerShell smoking (yes, smoking!)? The wildcard crack. You need to escape the square brackets like this "cd 'Excel Docs from my Sister `[2007`]'". Yeah, what a pain, too much typing.
What's an easier way of moving into that Excel directory? You can go "(ls).Get(0) | cd" to get the first folder returned by ls and pipe that into cd. That seems pretty cool until you realise all you're trying to do is cd into a damn directory. But it doesn't end there.
Put a couple of Word docs into Word Docs and also put a .txt file in there. Now maybe you would like to get only the Word docs and filter out any other file, so you do what you normally would: "Get-Item *.docx". What? Nothing found? How can that be? You can see the documents in there! The reason is that PowerShell is getting its knickers in a knot because its performing that command on the current working directory that happens contain square brackets in it. So it's trying to do some wildcards tomfoolery even though all you're trying to do is filter on only .docx files.
So how can you work around this? A few cmdlets let you pass in a -LiteralPath instead of a -Path, which will ignore the wildcard characters in the current path. But it won't work for this because we're trying to use wildcards to filter on .docx (the *). A solution is to do this: "Get-ChildItem | Where-Object {$_.Name -like "*.docx"}". But doesn't that just strike you as crap, considering we're supposed to be able to do fancy wildcard stuff easily, instead of manually like in that command?
"But Daniel", you say, "this only happens when you have directories that contain square brackets! Just do this tomfoolery when you encounter directories with brackets in them!". Sounds good, until you want to write a PowerShell script that does something and you can just reuse it wherever. The script I was writing would rename video files from one naming format to the one I prefer. It worked okay, until I tried to run it on a directory with brackets, then it crapped itself. What's the point of having this fancy wildcard stuff, if I can't use it because it means I'm writing a script that might break depending on whether the directories contain brackets?!
Just to rub salt in the wound, try to rename a file with brackets in its filename in Word Docs. Add a file called (and these are realistic names, the latter is how I name video files) "Pure Pwnage [s01e02] Girls.avi". Maybe you want to change the name to "Pure Pwnage [s01.e02] Girls.avi". Remembering you're probably doing this in a script, and so you can't just add in backticks to escape square brackets (unless you do a find and replace (LAME!)) you'll use -LiteralPath on Move-Item: "Move-Item -LiteralPath 'Pure Pwnage [s01e02] Girls.avi' -Destination 'Pure Pwnage [s01.e02] Girls.avi'".
That'll spit back the unintelligible "Could not find a part of the path" error. What does that mean!? Using the -Debug switch doesn't produce a more useful error message. Turns out -Destination takes wildcards so it's reading the "[" and "]" in the name as wildcards. That's fine, we'll just use -LiteralDestination. Except, there is no -LiteralDestination! Nice.
So how do we get around this (notice a pattern of having to get around things)? I found changing the -Destination to: ($PWD.Path + "\" + 'Pure Pwnage [s01.e02] Girls.avi') works. Basically we're prepending the Present Working Directory path to the filename. Then the rename works.
As you can see, as soon as you want to do things with files and folders with square brackets in them, PowerShell blows a gasket. Most of the time, this isn't an issue, until you want to write a script that doesn't just fall over and die at the sight of a square bracket. Which would be all the time, wouldn't it?
Hopefully, this crap will be fixed in PowerShell 2.0, not that I've actually looked to see if it is. Certainly it's incredibly frustrating. But to finish on an up note, I did make an awesome PowerShell script recently that showed the err... power... of PowerShell. I was reading in some XML output from the Subversion command line app, loading .NET's XML DOM parser, reading the XML into that, reading the DOM using XPath and doing stuff with the data, including sending an email to myself if the script encountered an error in the XML. That was awesome and easy to do when you're backed by the full .NET Framework. So I'm not writing PowerShell off just yet.
Generics and Type-Safety
September 06, 2008 3:00 PM by Daniel Chambers
I ran into a little issue at work to do with generics, inheritance and type-safety. Normally, I am an absolute supporter of type-safety in programming languages; I have always found that type safety catches bugs at compile-time rather than at run-time, which is always a good thing. However, in this particular instance (which I have never encountered before), type-safety plain got in my way.
Imagine you have a class Fruit, from which you derive a number of child classes such as Apple and Banana. There are methods that return Collection<Apple> and Collection<Banana>. Here's a code example (Java), can you see anything wrong with it (excluding the horrible wantApples/wantBananas code... I'm trying to keep the example small!)?
Collection<Fruit> fruit;
if (wantApples)
fruit = getCollectionOfApple();
else if (wantBananas)
fruit = getCollectionOfBanana();
else
throw new BabyOutOfPramException();
for (Fruit aFruit : fruit)
aFruit.eat();
Look OK? It's not. The error is that you cannot hold a Collection<Apple> or Collection<Banana> as a Collection<Fruit>! Why not, eh? Both Bananas and Apples are subclasses of Fruit, so why isn't a Collection of Banana a Collection of Fruit? All Bananas in the Collection are Fruit!
At first I blamed this on Java's crappy implementation of generics. In Java, generics are a compiler feature and not natively supported in the JVM. This is the concept of "type-erasure", where all generic type information is erased during a compile. All your Collections of type T are actually just Collections of no type. The most frustrating place where this bites you is when you want to do this:
interface MyInterface
{
private void myMethod(Collection<String> strings);
private void myMethod(Collection<Integer> numbers);
}
Java will not allow that, as the two methods are indistinguishable after a compile, thanks to type-erasure. Those methods actually are:
interface MyInterface
{
private void myMethod(Collection strings);
private void myMethod(Collection numbers);
}
and you get a redefinition error. Of course, .NET since v2.0 has treated generics as a first-class construct inside the CLR. So the equivalent to the above example in C# would work fine since a Collection<String> is not the same as a Collection<Integer>.
Anyway, enough ranting about Java. I insisted to my co-worker that I was sure C# with its non-crappy generics would have allowed us to assign a Collection<Apple> to a Collection<Fruit>. However, I was totally wrong. A quick Google search told me that you absolutely cannot allow a Collection<Apple> to be assigned to a Collection<Fruit> or it will break programming. This is why:
Collection<Fruit> fruit; Collection<Apple> apples = new ArrayList<Apple>(); fruit = apples; //Assume this line works OK fruit.add(new Banana()); for (Apple apple : apples) apple.eat();
Can you see the problem? By storing a Collection<Apple> as a Collection<Fruit> we suddenly make it OK to add any type of Fruit to the Collection, such as the Banana on line 4. Then, when we foreach through the apples Collection (which now contains a Banana, thanks to line 4) we would get a ClassCastException because, holy crap, a Banana is not an Apple! We just broke programming.
So how can we make this work? In Java, we can use wildcards:
Collection<? extends Fruit> fruit;
if (wantApples)
fruit = getCollectionOfApple();
else if (wantBananas)
fruit = getCollectionOfBanana();
else
throw new BabyOutOfPramException();
for (Fruit aFruit : fruit)
aFruit.eat();
Disappointingly, C# does not support the concept of wildcards. The best I could do was this:
private void MyMethod()
{
if (_WantApples)
EatFruit(GetEnumerableOfApples());
else if (_WantBananas)
EatFruit(GetEnumerableOfBananas());
else
throw new BabyOutOfPramException();
}
private void EatFruit<T>(IEnumerable<T> fruit) where T : Fruit
{
foreach (T aFruit in fruit)
aFruit.eat();
}
Basically, we're declaring a generic method that takes any type of Fruit, and then the compiler is inferring the type to be used for the EatFruit method by looking at the return type of the two getter methods. This code is not as nice as the Java code.
You must be wondering, however, what if we added this line to the bottom of the above Java code:
fruit.add(new Banana());
What would happen is that Java would issue an error. This is because the generic type "? extends Fruit" actually means "unknown type that extends Fruit". The "unknown type" part is crucial. Because the type is unknown, the add method for Collection<? extends Fruit> actually looks like this:
public boolean add(null o);
Yes! The only thing that the add method can take is null, because a reference to anything can always be set to null. So even though we don't know the type, we know that no matter what type it is, it can always be null. Therefore, trying to pass a Banana into add() would fail.
The foreach loop works okay because the iterator that works inside the foreach loop must always return something that is at least a Fruit thanks to the "extends Fruit" part of the type definition. So it's okay to set a Fruit reference using a method that returns "? extends Fruit" because the thing that is returned must be at least a Fruit.
Although obviously wrong now, the assignment of Collection<Apple> to Collection<Fruit> seemed to make sense when I first encountered it. This has enlightened me to the fact that there are nooks and crannies in both C# and Java that I have yet to explore.
PSD 2007
September 06, 2008 2:00 PM by Daniel Chambers
I wrote this blog on my phone in January 2008 and there it sat until I remembered about it today, 13 months since my last blog. Okay, so I've also been lazy. :)
So the year has ended and I haven't yet written about either of my semesters in the Professional Software Development course. Where 2006 was enjoyable and fun, 2007 was... how do I put this? Bloody hard? Death on a stick?
Either way, it was no cakewalk like I'm realising first year was.
This isn't to say I didn't enjoy it. I did, but... in hindsight. I certainly did not at the time. Why? The answer is simple. Too much bloody work. More than could be handled. Now I'm no slacker, I've achieved an easy HD average so far, so when I say there was too much work I don't mean there was too much work that it disturbed my slacking and games playing. Those activities (for me anyway) went mostly out the window years ago. I mean I put all my time and effort into the work and it still couldn't be achieved.
Still, all is not pain and misery. When I wasn't being worked into the ground I thoroughly enjoyed myself. The content of the course is still (mostly) well taught and relevant. I chose to take the Games stream for my specialisation, and this year was the first year those subjects came into play.
In first semester I took four subjects: Object Oriented Programming in C++, Data Communications and Security, Data Structures and Patterns and Software Development Practices. OOP in C++ was good for me because I taught myself C++ in 2002 but never really understood some of the more quirky and less used features that the language offers. This subject wasn't hard for me, having already done C++ for years, but I know it was difficult for my peers.
Data Structures and Patterns was a really good subject. Although many people found it really dull, I found it fascinating. The labs really supported the content: one lab got us to write an algorithm with linked lists and then again with arrays to illustrate where linked links perform poorly compared to arrays.
Software Development Practices took us through the process of speccing, designing and spiking out software projects. They tried to make the subject as practical as possible but it still could be really boring. There was no exam (thank god) which is good because regurgitating tonnes of theory is no fun.
Data Communications and Security was a good subject except that it attempted too much in too little a time. For example, one of our labs was to make UDP reliable. That's pretty massive. An assignment was to create a whole P2P filesharing system which also included splitting a file and downloading it from multiple sources. That's pretty massive. I really enjoyed the content of the subject, but man, the amount of work ruined the semester for me.
There was a fifth subject called Careers in the Curriculum where we were taught about job interviews and how to write a resume. Although it was annoying to have to do it when I already had too much work, I recognise it's usefulness now as I've needed to do interviews and write a resume.
In second semester, my four subjects were Database Programming, Languages in Software Development, Software Project Practices and Management and Games Programming. Database was a good subject, although I found it taught very little actual content, preferring to flog the crap out of 'the three layered architecture'. It did skim over some of the details of different database technologies like being able to program custom types into SQL Server 2005, but mostly it was about the three layered architecture. The hardest part about that subject was that it made you learn ASP.NET without any help at all and a rather short deadline. The actual database content was easy; it was the ASP.NET stuff that was hard because we had to learn it from scratch.
Languages in Software Development was odd. It was both a boring and fascinating subject. It seemed both irrelevant and relevant. Languages taught us about the basis of programming: lambda calculus. It was rather esoteric but also fascinating as we got to build a lambda calculus interpreter in Java. It also taught us about induction which was rather brain twisting and I still struggle with it. Our lecturer, Marcus, was wonderfully helpful and was willing to spend hours with me outside of class helping with the lambda calculus and induction problems I encountered. This subject required constant and considerable work, but was worth it.
Software Project Practices and Management was a subject that continued on from Software Development Practices. It started off a little dull but got better once it started talking about Extreme Programming practices and Scrum. Unlike SDP, it had an exam, which was a chore. I didn't end up doing the HD assignment because I simply didn't have time.
Games Programming was the big disappointment for me. That's not to say it was terrible, it just didn't live up to my expectations. Unfortunately, the subject was focussed towards Games and Multimedia students rather than PSDs and as such didn't actually contain enough programming. We spent half the semester writing a game design and not actually programming. This subject was like data comms in first semester: way too much work that took time away from other subjects and made the semester a nightmare. The distinction assignment was nothing less than, oh, write a whole game. Want an HD? Do a research report as well. It was basically impossible to do when you factor in the other subjects we had to do.
So, basically the year was good, just back breakingly difficult, but only because there simply was not enough time to complete all the allocated work. I'm looking forward to next year when I move to Adelaide to do my IBL year at the DSTO. The fixed work hours will mean I can't overwork myself like I did this year trying to do all the work in my subjects.
They say that second year is the hardest and it gets easier from there. I really hope so. In either case, it's over a year away so hopefully I'll be ready to take it on again by then. Now? I just want to play games and fiddle with Visual Studio 2008, .NET 3.5 and Windows Presentation Foundation. And sleep.
Scripting MP3 tagging
August 06, 2007 2:00 PM by Daniel Chambers
Lately, I've been getting annoyed at the state of my music and Audiobook collection. Each Audiobook can often be made up of hundreds (one has over a thousand) of small MP3s that allow me to easily skip through the book and also easily remember where I was up to.
But unfortunately, these small MP3s are not tagged and named correctly. Often, they are in correct order on the file system (alphabetically, by their filenames), but not by MP3 ID3 tag. This makes it a pain to play in my media player, especially on my iPod where there are practically no sorting functions.
I looked at various renaming and retagging solutions out on the web and after one of them completely scrambled one of my albums by putting the tag of each song on another song, I decided I needed something that just worked and was really flexible.
I always imagined how good it would be if I could just whip up a quick program to run through those thousand MP3s and name them correctly. So today I decided to create such a solution.
I wrote a small (~90 lines) console application in C++ called ID3CL (ID3 Command-Line) that uses the open source id3lib library to edit the ID3 tags of MP3 files. It takes in command-line arguments and retags a single MP3 file. Its command-line syntax is as follows:
Usage: id3cl <mp3 filename> -set <fieldname> <value>
[-set <field name> <value> [..]]
Fields: tracknum, artist, album, title, year
comment, genre
You basically invoke it like this: id3cl mysong.mp3 -set artist "DJ DC" -set title "Foobar on rocks". That will set the artist and title of the mysong.mp3 file.
Of course, this one-file-retagged-per-program-execution solution doesn't seem like it'd help me with retagging over 1000 MP3s does it? That's where scripting comes in.
I've recently been going nuts over PowerShell, the newish scripting language from Microsoft which is out to get rid of batch files (yay!). Writing PowerShell scripts is kind of a cross between writing C# and writing Bash. Its got some odd things in it (like '"{0:2D}" -f 2' will format 2 to be 02) which can make it almost as incomprehensible as Bash, but most of the time its a pleasure to work with (like C# and unlike Bash).
So, by writing a script in PowerShell which invokes my little C++ app (ID3CL), I can write tiny programs that retag my MP3 files any way I want.
Here's a little PowerShell script that takes MP3 files from the folder that the script is run in (and any files in folders under that one as well (recursively)) and changes their track numbers so the first one is 1 and the second 2, and so on.
$id3cl = "& 'D:\My Documents\Visual Studio 2005\Projects\ID3CL\release\id3cl.exe' "
$mp3s = Get-ChildItem * -Include *.mp3 -Recurse
$tracknum = 1
foreach ($mp3 in $mp3s)
{
$cmdline = '"' + $mp3.FullName + '" -set tracknum ' + $tracknum
Invoke-Expression ($id3cl + $cmdline)
$tracknum++
if ($tracknum -eq 256)
{
$tracknum = 1
}
}
This script is useful when I've got a two CD album, and I've got each CD from the album in its own folder. Each CD is treated like its own album with tracks starting from 1 and going on. But the thing is, I don't want to treat the album as two albums, I want one album with in-order track numbers. So that script will take CD1 and set the track numbers from 1 to X and then take CD2 and set the track numbers from X + 1 to Y. All automatically.
So you can see the power of this little system I've created. Unfortunately, only a programmer would be able to make use of this, since you've got to write scripts to do anything useful. But that's what makes it so powerful.
ID3CL is definitely me-ware. It's not user-friendly. It'll do silly things like if you get it to change the tag on a file that doesn't exist, it'll create a music-less MP3 and put your tags on it silently with no error. I can't be bothered fixing such bugs because it works perfectly when you treat it nicely and give it exactly what it expects. This initially made me not want to put it online for you guys to use, but I think I will anyway. Soon™ :). But if it errors because you did something odd with it, you'll have to figure out its unhelpful error messages.
However, I think its worth it for the power it gives you to tag your MP3 collection.
Drawing Framework
June 28, 2007 2:00 PM by Daniel Chambers
I was going to write about my recent forays into finding a decent PHP IDE, but Eclipse just released a new version (v3.3) of their IDE, so I'll have to try the new version out first.
So instead, I'm going to show off some coding work I've been doing for the last few days. Here, see me going hardcore with four panels of code at once.
{kind=link}
I've been working on Aurora, Pulse Development's upcoming CMS. It's written in PHP5 and is fully object-oriented. One of the annoying jobs when writing in PHP is "echo"ing out HTML and dealing with submittable forms. It's messy if you want to do the job properly. When I say properly, I mean it should behave nicely when you stuff up the form entry and it returns back to you. This means having your old values that you entered last time back in their boxes, and the erroring parts highlighted so its easy to see where you stuffed up the form. Some informative error messages wouldn't go astray either.
Previously, I'd written seven "panels" (rectangular areas on a webpage that do something) just using the normal echoing out of text. Since I've stepped up development during the Uni holidays I could see that I was going to go nuts if I had to hack out a tonne more panels in this manner. I needed some support.
In came the Aurora Drawing Framework. I basically designed and wrote a object oriented model for "drawing" a webpage (echoing out stuff). Its main requirements were to make the restoring of past submitted form values automatic and to make the presentation of form errors automatic. Also, since one of Aurora's main design goals is that the UI and control code be very separate so we can easily rip the UI off and write a new one, the Drawing Framework also needed to be easily extensible and changeable. Don't like the way a control is done? Fine! Extend your own class and do it your way. The rest of the framework will still work with you (thanks polymorphism!).
The Drawing Framework also helps eliminate some security concerns, eliminates accidental (HTML) syntax errors, reduces the complexity of the code when dealing with complex forms, and helps keep your page XHTML 1.0 Strict valid. All HTML attributes are automatically run through PHP's htmlentities() function which stops people accidentally or maliciously inserting code into your HTML and hijacking your form. All controls are drawn by the framework (you just set properties) so there will be no markup syntax errors (providing the framework isn't busted :D). Complex functions are built into the framework so they're no more than a function call away (no added cyclomatic complexity). Silly things that invalidate your XHTML like having two <option> tags with the "selected" attribute set in the one dropdown control are prevented, keeping your code "Stricter" (it doesn't force you, though. You can still put a form inside a form...).
After three iterations of design (the first two iterations mostly blurred into each other, as the second iteration evolved as I was implementing), I had bashed out a decent OO design. Here's a nice whiteboard showing the overall class hierarchy. (You probably want to open that in another window so you can see it as I rave on like a lunatic.)
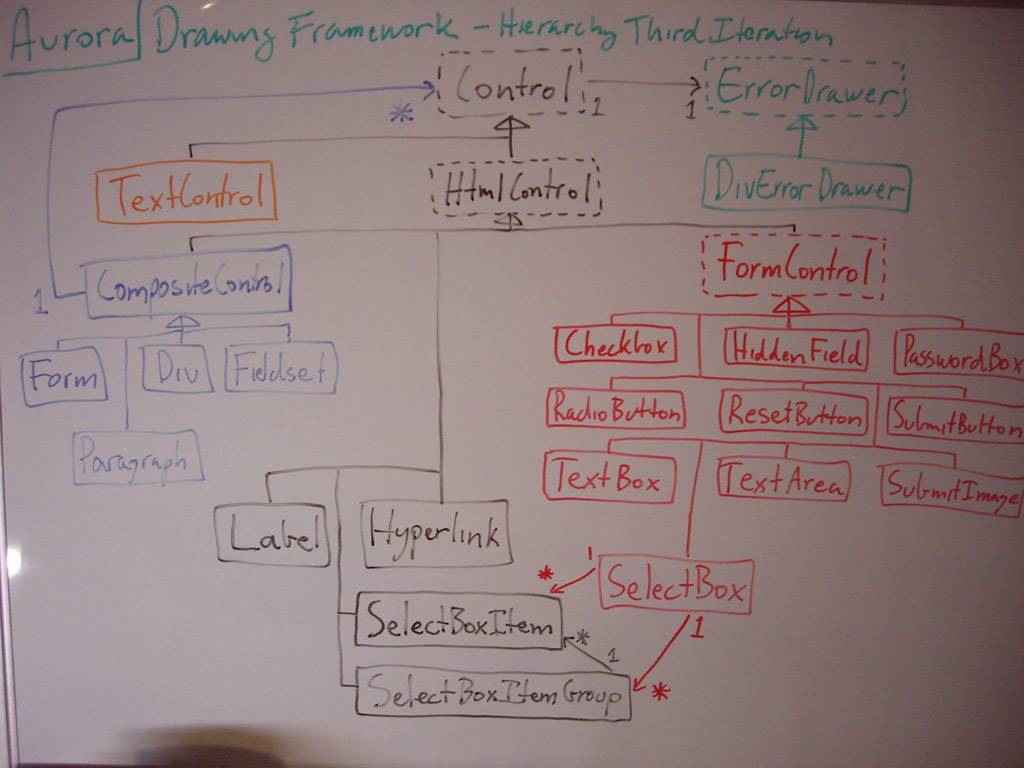{kind=link}
The Control class implements the interface through which the drawing is done, since every "control" is drawable. It also allows an ErrorDrawer to be used. The ErrorDrawer basically knows when errors happen and modifies the form HTML output code to display the errors to the user. Its abstract, so you can create different implementations of the ErrorDrawer that display the error differently. Maybe one will draw a red box around the offending control, and maybe another will put a (.NET style) little red exclamation icon next to the control. Its up to you.
Under Control, there is TextControl, which practically lets you "echo" anything out to the page HTML. It's supposed to be there to let you output text like the text inside a <p> tag. However, you can really use it to output anything (your risk and your responsibility). Then there is HtmlControl which deals with HTML controls. It provides some framework for its child classes to use, like HTML attribute handling and other things.
HtmlControl itself has two main subclasses, CompositeControl and FormControl. CompositeControls are ones that can contain other Controls (the Composite design pattern). FormControls are just that: form controls. FormControl implements the automatic previous value retrieval functionality, among other things.
Under those two classes you can see all the actual implementation classes. These are things that you actually use, like TextBoxes, SubmitButtons, Divs, Paragraphs, etc. Each one draws itself differently (obviously).
So, armed with this new framework, I went back to convert old panels across so that they use it. I was disappointed and pleased at the same time. It took more lines of code to output something simple using the Drawing Framework (but each line was a very short and simple method call) than using the old hacky echo method. However, when the form got more complex (it had error types and automatic past-value retrieval) then the Drawing Framework used less lines of code (still short and sweet lines). It was also now really easy to do those simple in concept but annoying and mistake-prone complex features.
So using the old hacky echoing method I'd probably output a form like this (it's a crappy example I know, but I don't want a massive load of code):
?>
<form action="form.php" method="post">
<input type="text" name="test" id="TestTB" />
</form>
<?php
Using the Drawing Framework for the same form:
$form = new Form();
$textBox = new TextBox();
$textBox->SetName("test");
$textBox->SetID("TestTB");
$form->AddControl($textBox);
$form->Draw();
As you can see it takes more lines. But to include error handling and auto past value retrieval it only changes to this:
$errorDrawer = new DivErrorDrawer($this, array("EmptyField", "BadTestData");
$form = new Form($errorDrawer);
$textBox = new TextBox(true);
$textBox->SetName("test");
$textBox->SetID("TestTB");
$form->AddControl($textBox);
$form->Draw();
The first line creates the DivErrorDrawer and tells it to get its error info from the current object (which is a panel), and to look for the EmptyField and BadTestData error types being set (these types are created and set by the panel). This ErrorDrawer is given to the form object, which means it will wrap its error illustration code around the form's code.
The "true" value now in the TextBox constructor turns on the auto past value code.
That's it. That's all you have to do. I'm not going to illustrate how you'd do the same thing using the echo method, but let me assure you that it would take more lines of code (not to mention the added code complexity). Actually, come to think of it, you can just make out some code mess on the second from the left code panel in this crappy blurry photo (with added 2x24" goodness! :P). You can kind of estimate the cyclomatic complexity of that code just by looking at the indentation (ick!).
Basically, writing code with the Drawing Framework is a bit like using the Java or .NET XML library, or the code that the Visual Studio form designer writes behind the scenes to create a desktop application form in .NET (which you can do manually, but who'd want to when you've got the designer?).
Although this looks cool and all, and is obviously useful, it seems that I'm really not adding that much value. But look to the future! In the future a "Control" could be more complex things like a Date Picker or a group of existing controls (like a sort of mini-panel) or even a text field that validates itself using Javascript and maybe does some AJAXy stuff (although some extensions would need to be made to the framework for it to support Javascript). The Drawing Framework has the potential to take the complexity out of complex forms (even though it adds complexity (or at least lines of code) to simple forms).
If you suddenly have the yearning to use the Drawing Framework, you'll have to wait a bit. Pulse Development is aiming to sell Aurora to web developers in the future, and the Drawing Framework is only a small part of it! Imagine what Aurora's going to be like!