
Only showing posts in the "Software Development" category
Broken Process Explorer: Missing .NET Performance Counters
September 28, 2008 3:00 PM by Daniel Chambers
For a while, I've had the problem where my .NET performance counters have been missing from my system. This had the side effect of breaking Process Explorer's ability to highlight which processes are .NET processes. Process Explorer checks for the presence of the performance counters to see whether .NET is installed, and if it doesn't find them it disables its .NET process detection.
Apparently a lot of people encounter this problem, since point 31 and 32 on the Process Explorer FAQ try to address it. However, the solutions they provide have never worked for me. However, recently I figured out what was stuffing it up. If you're in the same position as me and the FAQ doesn't help you, you might want to check this out. I run Vista x64, so if you're running XP still I can't guarantee this will work for you, since I haven't looked at it on XP.
Browse to HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\.NETFramework\Performance in regedit. Have a look at the "Library" value. Does it say "donotload_mscoree.dll"? If so, that's your problem. Change it to mscoree.dll and you're set. Apparently, MSDN says this about why it's not loaded:
If the .NET Framework is installed on a system that is running Windows XP, any process that uses the Performance Data Helper (PDH) functions to retrieve performance counters may stop responding ("hang") for 60 seconds when the process exits.
...
This delay is caused by a bug in the .NET Framework performance extension DLL, Mscoree.dll.
Hence, they recommend disabling the counters by renaming the library to donotload_mscoree.dll. That's an awesome solution, Microsoft! Why not just fix your bugs?! Luckily, they say it only applies to .NET 1.0 and 1.1, which are so old and irrelevent I wouldn't touch them with a barge pole (no generics, for christ's sake!). However, they haven't looked at this article since November 15, 2003, so maybe it still applies to .NET 2.0+. Who knows. You'd hope they'd have fixed this epic fail bug by now.
I reckon that Visual Studio or SQL Server must have made that change in the registry, because I don't have this problem on my computer at work (Java programming, so no VS). I've also always had this problem on my home machines and I've also always has VS installed on them. Hopefully, Microsoft didn't disable it for a good reason, because I've undone it now... but somehow I doubt they'd deliberately be breaking performance counters. After all, the people who actually use them are probably .NET developers and they almost definately use Visual Studio.
PowerShell Tries to be Smart, Shoots Self in Foot
September 27, 2008 2:00 PM by Daniel Chambers
I used to like PowerShell a lot. It seemed like a decent scripting language that extended the .NET Framework, so anything I could do in .NET I could do in PowerShell. That's still true, except I find that every time I try to use PowerShell to quickly whip up some small solution, I spend far too long messing around getting choked by its black magic. It would have been faster to write a command-line app in full blown C#.
I guess you could say that if I knew PowerShell better, this wouldn't happen, and that would be true. However, I don't write full blown applications in PowerShell... that's not what it's for. I'm not a sys-admin and don't want to be, so I don't spend a lot of time scripting. So the few times I want to write a quick script I just want to quickly crack out a script and have done with it.
My current rage against PowerShell has been evoked by the way it handles filepaths. PowerShell lets you put wildcards, such as [0-7] or *, into your paths that you pass to its cmdlets to do things. The problem occurs when the directories you are using contain characters that are used for wildcards (the square brackets, particularly). PowerShell totally craps out. I'll run you through a short example.
Create a directory called "Files [2000-2008]" in C:, then under that create two other directories "Word Docs" and "Excel Docs from my Sister [2007]". Open up PowerShell and cd to C:\Files [2000-2008]. Now type "cd" and try to use tab completion to go into Word Docs or Excel Docs. Oh what? It's not working? Yep, broken. Okay, so you'll have to type out "cd 'Word Docs'" to move into that directory. Dodgy, but no real problem.
Okay, now "cd .." back into Files. Now try to get into Excel Docs. Maybe you'll type (since tab completion is rooted) "cd 'Excel Docs from my Sister [2007]'". Nup, doesn't work, apparently it doesn't exist! What crack is PowerShell smoking (yes, smoking!)? The wildcard crack. You need to escape the square brackets like this "cd 'Excel Docs from my Sister `[2007`]'". Yeah, what a pain, too much typing.
What's an easier way of moving into that Excel directory? You can go "(ls).Get(0) | cd" to get the first folder returned by ls and pipe that into cd. That seems pretty cool until you realise all you're trying to do is cd into a damn directory. But it doesn't end there.
Put a couple of Word docs into Word Docs and also put a .txt file in there. Now maybe you would like to get only the Word docs and filter out any other file, so you do what you normally would: "Get-Item *.docx". What? Nothing found? How can that be? You can see the documents in there! The reason is that PowerShell is getting its knickers in a knot because its performing that command on the current working directory that happens contain square brackets in it. So it's trying to do some wildcards tomfoolery even though all you're trying to do is filter on only .docx files.
So how can you work around this? A few cmdlets let you pass in a -LiteralPath instead of a -Path, which will ignore the wildcard characters in the current path. But it won't work for this because we're trying to use wildcards to filter on .docx (the *). A solution is to do this: "Get-ChildItem | Where-Object {$_.Name -like "*.docx"}". But doesn't that just strike you as crap, considering we're supposed to be able to do fancy wildcard stuff easily, instead of manually like in that command?
"But Daniel", you say, "this only happens when you have directories that contain square brackets! Just do this tomfoolery when you encounter directories with brackets in them!". Sounds good, until you want to write a PowerShell script that does something and you can just reuse it wherever. The script I was writing would rename video files from one naming format to the one I prefer. It worked okay, until I tried to run it on a directory with brackets, then it crapped itself. What's the point of having this fancy wildcard stuff, if I can't use it because it means I'm writing a script that might break depending on whether the directories contain brackets?!
Just to rub salt in the wound, try to rename a file with brackets in its filename in Word Docs. Add a file called (and these are realistic names, the latter is how I name video files) "Pure Pwnage [s01e02] Girls.avi". Maybe you want to change the name to "Pure Pwnage [s01.e02] Girls.avi". Remembering you're probably doing this in a script, and so you can't just add in backticks to escape square brackets (unless you do a find and replace (LAME!)) you'll use -LiteralPath on Move-Item: "Move-Item -LiteralPath 'Pure Pwnage [s01e02] Girls.avi' -Destination 'Pure Pwnage [s01.e02] Girls.avi'".
That'll spit back the unintelligible "Could not find a part of the path" error. What does that mean!? Using the -Debug switch doesn't produce a more useful error message. Turns out -Destination takes wildcards so it's reading the "[" and "]" in the name as wildcards. That's fine, we'll just use -LiteralDestination. Except, there is no -LiteralDestination! Nice.
So how do we get around this (notice a pattern of having to get around things)? I found changing the -Destination to: ($PWD.Path + "\" + 'Pure Pwnage [s01.e02] Girls.avi') works. Basically we're prepending the Present Working Directory path to the filename. Then the rename works.
As you can see, as soon as you want to do things with files and folders with square brackets in them, PowerShell blows a gasket. Most of the time, this isn't an issue, until you want to write a script that doesn't just fall over and die at the sight of a square bracket. Which would be all the time, wouldn't it?
Hopefully, this crap will be fixed in PowerShell 2.0, not that I've actually looked to see if it is. Certainly it's incredibly frustrating. But to finish on an up note, I did make an awesome PowerShell script recently that showed the err... power... of PowerShell. I was reading in some XML output from the Subversion command line app, loading .NET's XML DOM parser, reading the XML into that, reading the DOM using XPath and doing stuff with the data, including sending an email to myself if the script encountered an error in the XML. That was awesome and easy to do when you're backed by the full .NET Framework. So I'm not writing PowerShell off just yet.
Generics and Type-Safety
September 06, 2008 3:00 PM by Daniel Chambers
I ran into a little issue at work to do with generics, inheritance and type-safety. Normally, I am an absolute supporter of type-safety in programming languages; I have always found that type safety catches bugs at compile-time rather than at run-time, which is always a good thing. However, in this particular instance (which I have never encountered before), type-safety plain got in my way.
Imagine you have a class Fruit, from which you derive a number of child classes such as Apple and Banana. There are methods that return Collection<Apple> and Collection<Banana>. Here's a code example (Java), can you see anything wrong with it (excluding the horrible wantApples/wantBananas code... I'm trying to keep the example small!)?
Collection<Fruit> fruit;
if (wantApples)
fruit = getCollectionOfApple();
else if (wantBananas)
fruit = getCollectionOfBanana();
else
throw new BabyOutOfPramException();
for (Fruit aFruit : fruit)
aFruit.eat();
Look OK? It's not. The error is that you cannot hold a Collection<Apple> or Collection<Banana> as a Collection<Fruit>! Why not, eh? Both Bananas and Apples are subclasses of Fruit, so why isn't a Collection of Banana a Collection of Fruit? All Bananas in the Collection are Fruit!
At first I blamed this on Java's crappy implementation of generics. In Java, generics are a compiler feature and not natively supported in the JVM. This is the concept of "type-erasure", where all generic type information is erased during a compile. All your Collections of type T are actually just Collections of no type. The most frustrating place where this bites you is when you want to do this:
interface MyInterface
{
private void myMethod(Collection<String> strings);
private void myMethod(Collection<Integer> numbers);
}
Java will not allow that, as the two methods are indistinguishable after a compile, thanks to type-erasure. Those methods actually are:
interface MyInterface
{
private void myMethod(Collection strings);
private void myMethod(Collection numbers);
}
and you get a redefinition error. Of course, .NET since v2.0 has treated generics as a first-class construct inside the CLR. So the equivalent to the above example in C# would work fine since a Collection<String> is not the same as a Collection<Integer>.
Anyway, enough ranting about Java. I insisted to my co-worker that I was sure C# with its non-crappy generics would have allowed us to assign a Collection<Apple> to a Collection<Fruit>. However, I was totally wrong. A quick Google search told me that you absolutely cannot allow a Collection<Apple> to be assigned to a Collection<Fruit> or it will break programming. This is why:
Collection<Fruit> fruit; Collection<Apple> apples = new ArrayList<Apple>(); fruit = apples; //Assume this line works OK fruit.add(new Banana()); for (Apple apple : apples) apple.eat();
Can you see the problem? By storing a Collection<Apple> as a Collection<Fruit> we suddenly make it OK to add any type of Fruit to the Collection, such as the Banana on line 4. Then, when we foreach through the apples Collection (which now contains a Banana, thanks to line 4) we would get a ClassCastException because, holy crap, a Banana is not an Apple! We just broke programming.
So how can we make this work? In Java, we can use wildcards:
Collection<? extends Fruit> fruit;
if (wantApples)
fruit = getCollectionOfApple();
else if (wantBananas)
fruit = getCollectionOfBanana();
else
throw new BabyOutOfPramException();
for (Fruit aFruit : fruit)
aFruit.eat();
Disappointingly, C# does not support the concept of wildcards. The best I could do was this:
private void MyMethod()
{
if (_WantApples)
EatFruit(GetEnumerableOfApples());
else if (_WantBananas)
EatFruit(GetEnumerableOfBananas());
else
throw new BabyOutOfPramException();
}
private void EatFruit<T>(IEnumerable<T> fruit) where T : Fruit
{
foreach (T aFruit in fruit)
aFruit.eat();
}
Basically, we're declaring a generic method that takes any type of Fruit, and then the compiler is inferring the type to be used for the EatFruit method by looking at the return type of the two getter methods. This code is not as nice as the Java code.
You must be wondering, however, what if we added this line to the bottom of the above Java code:
fruit.add(new Banana());
What would happen is that Java would issue an error. This is because the generic type "? extends Fruit" actually means "unknown type that extends Fruit". The "unknown type" part is crucial. Because the type is unknown, the add method for Collection<? extends Fruit> actually looks like this:
public boolean add(null o);
Yes! The only thing that the add method can take is null, because a reference to anything can always be set to null. So even though we don't know the type, we know that no matter what type it is, it can always be null. Therefore, trying to pass a Banana into add() would fail.
The foreach loop works okay because the iterator that works inside the foreach loop must always return something that is at least a Fruit thanks to the "extends Fruit" part of the type definition. So it's okay to set a Fruit reference using a method that returns "? extends Fruit" because the thing that is returned must be at least a Fruit.
Although obviously wrong now, the assignment of Collection<Apple> to Collection<Fruit> seemed to make sense when I first encountered it. This has enlightened me to the fact that there are nooks and crannies in both C# and Java that I have yet to explore.
Scripting MP3 tagging
August 06, 2007 2:00 PM by Daniel Chambers
Lately, I've been getting annoyed at the state of my music and Audiobook collection. Each Audiobook can often be made up of hundreds (one has over a thousand) of small MP3s that allow me to easily skip through the book and also easily remember where I was up to.
But unfortunately, these small MP3s are not tagged and named correctly. Often, they are in correct order on the file system (alphabetically, by their filenames), but not by MP3 ID3 tag. This makes it a pain to play in my media player, especially on my iPod where there are practically no sorting functions.
I looked at various renaming and retagging solutions out on the web and after one of them completely scrambled one of my albums by putting the tag of each song on another song, I decided I needed something that just worked and was really flexible.
I always imagined how good it would be if I could just whip up a quick program to run through those thousand MP3s and name them correctly. So today I decided to create such a solution.
I wrote a small (~90 lines) console application in C++ called ID3CL (ID3 Command-Line) that uses the open source id3lib library to edit the ID3 tags of MP3 files. It takes in command-line arguments and retags a single MP3 file. Its command-line syntax is as follows:
Usage: id3cl <mp3 filename> -set <fieldname> <value>
[-set <field name> <value> [..]]
Fields: tracknum, artist, album, title, year
comment, genre
You basically invoke it like this: id3cl mysong.mp3 -set artist "DJ DC" -set title "Foobar on rocks". That will set the artist and title of the mysong.mp3 file.
Of course, this one-file-retagged-per-program-execution solution doesn't seem like it'd help me with retagging over 1000 MP3s does it? That's where scripting comes in.
I've recently been going nuts over PowerShell, the newish scripting language from Microsoft which is out to get rid of batch files (yay!). Writing PowerShell scripts is kind of a cross between writing C# and writing Bash. Its got some odd things in it (like '"{0:2D}" -f 2' will format 2 to be 02) which can make it almost as incomprehensible as Bash, but most of the time its a pleasure to work with (like C# and unlike Bash).
So, by writing a script in PowerShell which invokes my little C++ app (ID3CL), I can write tiny programs that retag my MP3 files any way I want.
Here's a little PowerShell script that takes MP3 files from the folder that the script is run in (and any files in folders under that one as well (recursively)) and changes their track numbers so the first one is 1 and the second 2, and so on.
$id3cl = "& 'D:\My Documents\Visual Studio 2005\Projects\ID3CL\release\id3cl.exe' "
$mp3s = Get-ChildItem * -Include *.mp3 -Recurse
$tracknum = 1
foreach ($mp3 in $mp3s)
{
$cmdline = '"' + $mp3.FullName + '" -set tracknum ' + $tracknum
Invoke-Expression ($id3cl + $cmdline)
$tracknum++
if ($tracknum -eq 256)
{
$tracknum = 1
}
}
This script is useful when I've got a two CD album, and I've got each CD from the album in its own folder. Each CD is treated like its own album with tracks starting from 1 and going on. But the thing is, I don't want to treat the album as two albums, I want one album with in-order track numbers. So that script will take CD1 and set the track numbers from 1 to X and then take CD2 and set the track numbers from X + 1 to Y. All automatically.
So you can see the power of this little system I've created. Unfortunately, only a programmer would be able to make use of this, since you've got to write scripts to do anything useful. But that's what makes it so powerful.
ID3CL is definitely me-ware. It's not user-friendly. It'll do silly things like if you get it to change the tag on a file that doesn't exist, it'll create a music-less MP3 and put your tags on it silently with no error. I can't be bothered fixing such bugs because it works perfectly when you treat it nicely and give it exactly what it expects. This initially made me not want to put it online for you guys to use, but I think I will anyway. Soon™ :). But if it errors because you did something odd with it, you'll have to figure out its unhelpful error messages.
However, I think its worth it for the power it gives you to tag your MP3 collection.
Drawing Framework
June 28, 2007 2:00 PM by Daniel Chambers
I was going to write about my recent forays into finding a decent PHP IDE, but Eclipse just released a new version (v3.3) of their IDE, so I'll have to try the new version out first.
So instead, I'm going to show off some coding work I've been doing for the last few days. Here, see me going hardcore with four panels of code at once.
{kind=link}
I've been working on Aurora, Pulse Development's upcoming CMS. It's written in PHP5 and is fully object-oriented. One of the annoying jobs when writing in PHP is "echo"ing out HTML and dealing with submittable forms. It's messy if you want to do the job properly. When I say properly, I mean it should behave nicely when you stuff up the form entry and it returns back to you. This means having your old values that you entered last time back in their boxes, and the erroring parts highlighted so its easy to see where you stuffed up the form. Some informative error messages wouldn't go astray either.
Previously, I'd written seven "panels" (rectangular areas on a webpage that do something) just using the normal echoing out of text. Since I've stepped up development during the Uni holidays I could see that I was going to go nuts if I had to hack out a tonne more panels in this manner. I needed some support.
In came the Aurora Drawing Framework. I basically designed and wrote a object oriented model for "drawing" a webpage (echoing out stuff). Its main requirements were to make the restoring of past submitted form values automatic and to make the presentation of form errors automatic. Also, since one of Aurora's main design goals is that the UI and control code be very separate so we can easily rip the UI off and write a new one, the Drawing Framework also needed to be easily extensible and changeable. Don't like the way a control is done? Fine! Extend your own class and do it your way. The rest of the framework will still work with you (thanks polymorphism!).
The Drawing Framework also helps eliminate some security concerns, eliminates accidental (HTML) syntax errors, reduces the complexity of the code when dealing with complex forms, and helps keep your page XHTML 1.0 Strict valid. All HTML attributes are automatically run through PHP's htmlentities() function which stops people accidentally or maliciously inserting code into your HTML and hijacking your form. All controls are drawn by the framework (you just set properties) so there will be no markup syntax errors (providing the framework isn't busted :D). Complex functions are built into the framework so they're no more than a function call away (no added cyclomatic complexity). Silly things that invalidate your XHTML like having two <option> tags with the "selected" attribute set in the one dropdown control are prevented, keeping your code "Stricter" (it doesn't force you, though. You can still put a form inside a form...).
After three iterations of design (the first two iterations mostly blurred into each other, as the second iteration evolved as I was implementing), I had bashed out a decent OO design. Here's a nice whiteboard showing the overall class hierarchy. (You probably want to open that in another window so you can see it as I rave on like a lunatic.)
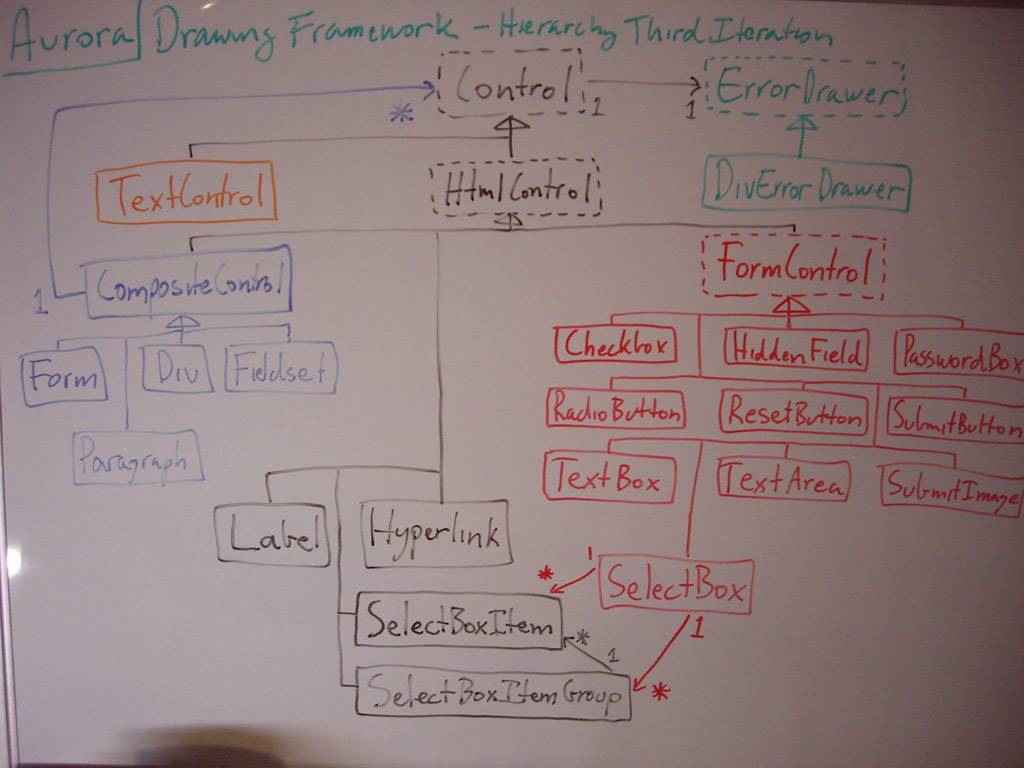{kind=link}
The Control class implements the interface through which the drawing is done, since every "control" is drawable. It also allows an ErrorDrawer to be used. The ErrorDrawer basically knows when errors happen and modifies the form HTML output code to display the errors to the user. Its abstract, so you can create different implementations of the ErrorDrawer that display the error differently. Maybe one will draw a red box around the offending control, and maybe another will put a (.NET style) little red exclamation icon next to the control. Its up to you.
Under Control, there is TextControl, which practically lets you "echo" anything out to the page HTML. It's supposed to be there to let you output text like the text inside a <p> tag. However, you can really use it to output anything (your risk and your responsibility). Then there is HtmlControl which deals with HTML controls. It provides some framework for its child classes to use, like HTML attribute handling and other things.
HtmlControl itself has two main subclasses, CompositeControl and FormControl. CompositeControls are ones that can contain other Controls (the Composite design pattern). FormControls are just that: form controls. FormControl implements the automatic previous value retrieval functionality, among other things.
Under those two classes you can see all the actual implementation classes. These are things that you actually use, like TextBoxes, SubmitButtons, Divs, Paragraphs, etc. Each one draws itself differently (obviously).
So, armed with this new framework, I went back to convert old panels across so that they use it. I was disappointed and pleased at the same time. It took more lines of code to output something simple using the Drawing Framework (but each line was a very short and simple method call) than using the old hacky echo method. However, when the form got more complex (it had error types and automatic past-value retrieval) then the Drawing Framework used less lines of code (still short and sweet lines). It was also now really easy to do those simple in concept but annoying and mistake-prone complex features.
So using the old hacky echoing method I'd probably output a form like this (it's a crappy example I know, but I don't want a massive load of code):
?>
<form action="form.php" method="post">
<input type="text" name="test" id="TestTB" />
</form>
<?php
Using the Drawing Framework for the same form:
$form = new Form();
$textBox = new TextBox();
$textBox->SetName("test");
$textBox->SetID("TestTB");
$form->AddControl($textBox);
$form->Draw();
As you can see it takes more lines. But to include error handling and auto past value retrieval it only changes to this:
$errorDrawer = new DivErrorDrawer($this, array("EmptyField", "BadTestData");
$form = new Form($errorDrawer);
$textBox = new TextBox(true);
$textBox->SetName("test");
$textBox->SetID("TestTB");
$form->AddControl($textBox);
$form->Draw();
The first line creates the DivErrorDrawer and tells it to get its error info from the current object (which is a panel), and to look for the EmptyField and BadTestData error types being set (these types are created and set by the panel). This ErrorDrawer is given to the form object, which means it will wrap its error illustration code around the form's code.
The "true" value now in the TextBox constructor turns on the auto past value code.
That's it. That's all you have to do. I'm not going to illustrate how you'd do the same thing using the echo method, but let me assure you that it would take more lines of code (not to mention the added code complexity). Actually, come to think of it, you can just make out some code mess on the second from the left code panel in this crappy blurry photo (with added 2x24" goodness! :P). You can kind of estimate the cyclomatic complexity of that code just by looking at the indentation (ick!).
Basically, writing code with the Drawing Framework is a bit like using the Java or .NET XML library, or the code that the Visual Studio form designer writes behind the scenes to create a desktop application form in .NET (which you can do manually, but who'd want to when you've got the designer?).
Although this looks cool and all, and is obviously useful, it seems that I'm really not adding that much value. But look to the future! In the future a "Control" could be more complex things like a Date Picker or a group of existing controls (like a sort of mini-panel) or even a text field that validates itself using Javascript and maybe does some AJAXy stuff (although some extensions would need to be made to the framework for it to support Javascript). The Drawing Framework has the potential to take the complexity out of complex forms (even though it adds complexity (or at least lines of code) to simple forms).
If you suddenly have the yearning to use the Drawing Framework, you'll have to wait a bit. Pulse Development is aiming to sell Aurora to web developers in the future, and the Drawing Framework is only a small part of it! Imagine what Aurora's going to be like!
SDP Blog - Critique
May 14, 2007 2:00 PM by Daniel Chambers
This is the fourth blog I am doing for my Software Development Practices subject.
Eudora is an email client that I use to access my various email accounts via POP. It does the job admirably and I have been using it for years. Relatively recently, an update to Eudora added instant search functionality, presumably to combat all the other instant search products that have been hitting the market over the last few years. It was a good idea, as doing a normal search through your email tended to take a while.
The Eudora development team took the easy way out: they licensed a third party instant search product called X1 and integrated into Eudora. Unfortunately, this is where the good idea started to come apart. The fast search often does not find results, even though you know there are emails that would match your search parameters. This seems to happen mostly for newish messages, making me think that perhaps the X1 search engine is not having its search index updated in a timely manner. This is an annoying and misleading problem, since most users trust the output of their search request. If their result set is missing some emails, they probably won’t notice and will miss things.
I would probably blame this problem on a lack of testing. Eudora was late to the indexed-search party and perhaps the development team rushed the implementation and skimped on the testing just to get the product out of the door. Not a good move. My theory is lent credence by the fact that the Eudora team chose to integrate a third-party search solution rather than write their own, like every vendor seems to be doing currently. They needed a solution quickly, so instead of spending time writing their own, they used X1.
When specifying the requirements for the new indexed-search feature, the Eudora team probably forgot to define some clear quality requirements that should have specified the regularity at which the search index was to be updated, if indeed that is the problem. Of course, this is such a blatant problem that it really should have been picked up in the test phase. This indicates lax procedures behind the running of the software testing activities.
To fix these sorts of problems in the future, the Eudora team should be very careful and specify all quality requirements during the specification phase. This should be backed up by a more stringent test phase before the product goes live. The team should try not to rush the product out the door; in my opinion, its better late than critically broken.
Unfortunately, since Eudora is no longer being sold by Qualcomm (the company behind Eudora), this bug is probably not going to be fixed. Luckily, there is an option to turn off the indexed-search and use the old search. It may take a few seconds to return results, but at least it returns them all.
SDP Blog - Vision Statements
May 01, 2007 3:00 PM by Daniel Chambers
This is the second blog I am doing for my Software Development Practices subject.
Visions statements are used to broadly state the goals and objectives of a project. Vision statements are distinct from mission statements in that they describe a vision for the future rather than focusing on the immediate.
There is a simple template you can fill out to help you focus your ideas into a vision statement. You need to answer these six sections:
- For some audience...
Who are the groups of people that your product is going to target?
eg. PC gamers - Who have a problem...
What seems to be the problem that these groups are having?
eg. They do not have a real-time strategy game that allows large-scale strategy - Our product called x...
What is the product's name and what category of solution does it lie in?
eg. Supreme Commander is an RTS PC game - That solves the problem by...
What is the main reason that would persuade these groups to use your solution?
eg. It allows large-scale strategy games over huge maps with hundreds of units - Unlike...
Who are your main competitors?
eg. Company of Heroes - Our product is different because...
How is your product better than your competitor's product?
eg. Supreme Commander allows the player to focus on strategy rather than tactics
Once you’ve answered those questions, you can string your answers together and use some English grammar skills to make it sound smooth. To continue the example I used:
Supreme Commander is a real-time strategy game for PC gamers who want to play large-scale strategy games over huge maps with hundreds of units. Unlike Company of Heroes, Supreme Commander allows the player to focus on strategy rather than tactics.
You might want to see what a real-world company uses for a vision statement. McDonalds uses this:
McDonald's vision is to be the world's best quick service restaurant experience. Being the best means providing outstanding quality, service, cleanliness and value, so that we make every customer in every restaurant smile.
All your projects should have a vision statement. When evaluating your solution you can always refer back to the vision statement and see if it matches your original vision.
RSS Feeds Have Changed and LemonWire
April 30, 2007 2:00 PM by Daniel Chambers
I have converted the RSS feeds on this site into FeedBurner feeds. Please unsubscribe from your current feeds and resubscribe to get the new URLs. This change should allow me to track the feeds' usage, which could be fun. I've gone a little statistics crazy since the bandwidth stealing episode, so now everything is all statted up. Sweet.
This will be a short blog this time, since I've got a ridiculous amount of Uni work to do. Swinburne has taken away the swat vac week that everyone uses for study before exams. So I get a grand two days to study for one of my subjects. Thanks Swinburne! [sarcasm].
One of our assignments is to write a P2P filesharing system (yes, you read that correctly) by the end of the semester. My team has spent the last 2 or so weeks planning; we haven't even written a line of code yet. We've written two documents describing the two protocols we're going to use and 23 whiteboards of object design. A lot of other groups have already begun coding but I think that's a bad idea. If there is one thing that the PSD course has taught me it is that starting a project by hacking some code is a good way to screw it up, especially in object oriented programs. Plan first, cut code later.
This seems to me to be especially important when you are working in a group. There are four people working in my group (including me). Without an OO design, everyone is going to do their own little thing and its just going to become a complete mess. Now that our design is done we can split the work between us and write the code knowing exactly what services someone else's part of the program will provide to my part.
The assignment's subject gives no guidance on how to code effectively in a group, which is crap since its a difficult thing to do effectively. Luckily, a few of us have some experience with source control before from a previous subject and I use source control at work. I've set up a Subversion repository for us all to work from on my home server. Hopefully, we won't make a mess when we use it.
We've named the program "LemonWire". This name has two tricks behind it. The first is obvious: a play on the common LimeWire P2P filesharing system. The second is less obvious: it works with the program's catchphrase: "its a lemon". Sounds random? Its not. Normally, when you say something's a lemon you mean that its not very good. The catchphrase basically reflects our cynicism with the assignment, since all of us reckon its way to big to be given to us to do in half a semester especially when we're missing swat vac. That and the fact that its a P2P filesharing system operated from a console! Also, a whole bunch of its architectural decisions are bad ones because we were forced to comply with the assignment spec. A good example is the fact that the network has a central server whose primary function is to bootstrap clients into the network. That ought to be done by another client, not a server. It would make sense if the server also indexed shared files and performed searches, but it doesn't.
I may have sounded a little too cynical about our ability to complete the assignment in the last paragraph. Its true that it is much too big for an assignment, but I think if we all work hard on it, we have a good chance of completing it in time, thanks to our time spent planning. Wish us luck!
The next few blogs are going to be blogs that I have to write for my Software Development Practices subject. One of the requirements is that I put the blogs online, so I'm putting them here. They may be a little dry, but hey, maybe you'll learn something!
So much for a short blog.
Working Hard
December 05, 2006 2:00 PM by Daniel Chambers
Even though its the holidays, I have been working harder than ever. Currently, I'm working two days a week at my part-time job and the other three days at the Summer Scholarship at my university. Unfortunately, my preferred living style (going to bed really late and waking up as late as possible) doesn't work well with 5 days a week of full time work, so I've been tired as hell.
Luckily the work is mostly good: in my part-time job I have starting to be elevated from a mere software tester to a software developer. I wrote my first bit of code (in ColdFusion) for them on Monday! The Summer Scholarship is also great. I've been assigned a task where I have to create a simple API for creating games in the Pascal programming language, and to demonstrate that API with a side-scrolling game. The API will be used by next year's PSDs in their Algorithmic Problem Solving subject.
Writing the API in Pascal sucks, because I love real IDEs with code suggesting (Intellisense), and I'm using Crimson Editor (simple as hell text editor) to write my Pascal. Also, Pascal isn't exactly a language that is widespread, so learning it hardcore is (almost) wasted. I can't even use the object oriented features of the language since the APS students won't know OOP yet! The other guys get to write in C#, Java and PHP! But knowing that next year's APS students will use what I write makes it worthwhile and mollifies me.
Most of my blogging over the next three weeks will probably be on the Summer Scholarship's PictBlog at Blogspot, so keep an eye on that. As a side note, Blogspot's blog editor sucks. I had to edit my post there at least six times before it was correct. The worst problem was, for some reason, my text didn't word wrap and it poked out over the right-side navigation menu (overlapping it) and stretched the page. Hopeless.
Outside of work, I have also been busy writing the PHP for Aurora, the CMS that will power web solutions created by Pulse Development (my cousin and I's web design business). Aurora is written in PHP and I was happy to find that PHP 5 has almost all the OOP features that C# has: interfaces, inheritance, polymorphism, etc.
Aurora will power this website once its done (in fact I'll use DigitallyCreated as a kind of test bed for Aurora), so you'll get a nicer blog and news interface, and it'll be a hell of a lot easier for me to update it (hopefully increasing my blog count). Also, you've probably noticed this page getting stupidly long; Aurora will split it automatically over multiple pages. It will also do automatic generation of the RSS feeds for this blog (thank god, I do it manually at the moment!).
Finishing up, I'll leave you with a warning: I read an article over at the INQ about one of their reporters who got RSI (yes, that thing you ignore the warnings about). The afflicted hack wrote an article about his experiences with RSI and it sounds entirely nasty. He ended up with arms that didn't work. Normally, I don't really read this sort of stuff, let alone get worried about it, but this hits close to home since I do a lot of typing and I really don't want to break my livelihood (you can't code C# with speech recognition when your arms are stuffed). I would suggest you read it, so as to avoid it yourself. Find the article here.
Just a Little Wibble
November 14, 2006 2:00 PM by Daniel Chambers
Bah, I seem to be attracting hardware failures of late. The new stick of RAM I bought for my laptop in June decided to up and die, corrupting my Windows installation along with it. Luckily it has lifetime warranty, so I didn't lose anything, except my patience with the sluggish remaining 512MB of "not enough" RAM and having to reinstall everything which sucks when you're a developer (it takes ages).
But let's move onto the more interesting things. What I've begun doing is having a folder in my bookmarks in Opera, and when I get a particularly interesting article I stick it in there to write about later. This should mean I will blog more frequently*.
* Terms and Conditions Apply. :)
So. The first item: Windows PowerShell has gone 1.0! As we all know, the standard command prompt and scripting offered in Windows blows when compared to Bash in Linux. PowerShell is here to rectify that. However, don't go jumping into it thinking that you can just run all of Windows from the shell. Windows is still a strongly GUI-centred operating system and you can't just run the OS from the command-line like you can in Linux. Certainly it has been touted to make Windows Server administrators' lives easier, but unlike Linux, most apps for Windows aren't written with command-line functionality or COM interfaces.
The PowerShell syntax is a weird amalgam of C# syntax with a little Bash and some weirdness thrown in there for good measure. I almost wish it was more C#ish; just some things like the equality operator being -eq, as opposed to the more C-style ==, seem strange when you are doing C# style foreach loops.
Where Bash is often centered around plain text hacking, PowerShell does it differently. When you "pipe" things around you are piping objects. Yes, PowerShell is weirdly object oriented. Kind of. PowerShell is built on top of the .NET Framework, and it shows through. Passing objects around instead of plain strings is better since different cmdlets (pronounced "command-lets", these are the commands in PowerShell) can act on the objects differently without the need of string hacking ala Bash. For example, instead of (in Bash) getting a list of files, using awk to rip out the filenames then throwing them into file, PowerShell does it by getting objects that represent the files and passing those objects to some other command which will extract the filename object property and write them to a file. Its a crappy example, I know, but I haven't spent a lot of time in PowerShell yet. :)
If you're interested, you can download PowerShell here, and read a rather good starter tutorial here. In my summer holidays I'm looking forward to fiddling around more in PowerShell.
The next item on today's agenda: threading in the Source Engine! If you don't know what the Source Engine is you either live under the "I don't play computer games" rock or you play way too much Starcraft. For you people, the Source Engine is the game engine that powers the bestselling Half-Life 2 game and has been licenced for other good games like Dark Messiah - Might and Magic, and Sin Episodes.
Most game engines these days don't properly take use of dual/quad core CPUs because they are not "multithreaded". A program that is multithreaded has multiple lines of execution all running concurrently. This means, on a multi-core computer, more than one thing is happening at once. If your game isn't threaded it pretty much means a whole half (or three-quarters or whatever) of your CPU is going to waste. So its an important thing for games to become multithreaded.
Valve (the makers of the Source Engine, oh uneducated ones :P) have started work on making the Source Engine multithreaded. This is difficult since threading can be a real pain in the butt and will require a large amount of the engine to be rewritten. There are three main ways that multithreading can be done in a game engine: in a coarse fashion, in a fine fashion, and in a hybrid fashion that uses elements from both coarse and fine.
The coarse fashion is where different game subsystems are put on different threads. Valve found this to be ineffective in utilising the entire CPU fulltime. The fine fashion is where low level tasks are split across cores. This method was also unsatisfactory since not all tasks are well suited to being split in this fashion. Valve settled on the hybrid method which pretty much means it uses the coarse fashion where it suits the problem and the fine fashion where it suits the problem. This way is the most complex but it scales well and maxes out the CPU.
What Valve has done is to create N-1 threads (for N cores on the CPU) with the other thread being the master controller thread. Valve uses lock-free algorithms to help remove the problem of threads sitting around blocking (doing nothing) while they wait for access to data (two threads cannot write to the same piece of data at the same time, that would be bad).
Multithreading in Source can only bring benefits to Source-based games. I know that currently half of my CPU (1 core of 2) sits around doing nothing when I play games, and last time I checked I didn't fork out good cash for it to be slacking! There is a full on article about multithreaded Source which goes into more detail and has a good focus on the technical side of the threading, which a lot of the other articles about this didn't.
A nice thing to hear is that Valve uses iterative development on the Source Engine (building and improving it piece by piece over time, rather than writing it and then rewriting it from scratch for upgrades) because my course at University likes to rave about iterative development. Wonder whether they do unit tests :).
And finally on today's show is a little something to back up my rant on Apple a few blogs ago. I will now degrade into IM-speak: LOFL, ROFLMAO, LOL.